

When it comes to microservices and distributed systems, you need to see the full picture and the small details. But how do you get visibility?
Intro
Microservices have tons of benefits.
They enable distributed development of highly scalable applications and unleashing the full potential of public cloud infrastructure.
But there can be no good without evil.
Microservices are DIFFICULT to understand and troubleshoot.
When done right, microservices are asynchronous, which means each service can operate without relying on other services, and the communication between services does not depend on any particular order of events, making it extremely challenging to understand and track.
Services can obviously communicate with one another directly but by doing so, you are basically creating a dependency that will affect the robustness of your system and how complicated it is to add functionality.
So when dealing with microservices, it’s not enough to understand the state of a particular service, you need also to understand the interactions between its different components.
To put it differently, without the proper setup, you lack the timeline of requests between services and the cause and effect of different events in your system.
You lack context.
The popular way to achieve asynchronous relations between services is by having services communicating by exchanging messages - aka asynchronous messaging or message brokers.
Async messaging plays a crucial role in distributed systems architecture, making it easier to build complex systems using microservices.
Communicating over a message broker minimizes the mutual awareness that services should have of each other in order to be able to exchange messages, effectively implementing decoupling which is the root idea of microservices.
But now, understanding the path of each message, where it goes, why, and when, is both critical, and here is the hard truth, a nightmare. (more on that later).
In short, when it comes to microservices and distributed systems, you need to see the full picture and the small details.
That's the only way you could gain that visibility into what happens (or doesn't) in your systems and how to deal with it.
But how do you get visibility?
OpenTelemetry to The Rescue 🔭
OpenTelemetry is a set of tools built to enable instrumentation, gathering and generating telemetry data. It is an open source and a member of the CNCF - the Cloud Native Computing Foundation.
It provides us with the missing piece of this microservices communication puzzle - context - by allowing us to gather data on each request that happens in our distributed system.
Think of it as a middleware, enabled via an sdk (in each microservice), that collects data about the calls the service is executing. Whether the call is to a messaging queue, database or another service.
Its power comes from its ability to maintain context propagation - we can store context on top of each request, thus enabling us to group related operations together, and create these graphs automatically.
The Fun Part - Gaining Visibility Using ExpressJS, Kafka, OpenTelemetry and Zipkin
Here’s how you actually implement OpenTelemetry in microservices to understand async messaging in your system.
There are many great async messaging tools out there that you can use for your services communication (AWS SQS, Kafka, RabbitMQ, just to name a few).
Due to its popularity and ease of use we have selected Kafka for this tutorial.
Step 1 - Create a docker-compose.yml file to run Kafka
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper:latest
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka:2.11-1.1.1
ports:
- "9092:9092"
links:
- zookeeper
environment:
KAFKA_ADVERTISED_HOST_NAME: ${HOST_IP}
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'true'
KAFKA_DELETE_TOPIC_ENABLE: 'true'
KAFKA_CREATE_TOPICS: "topic-test:1:1"
volumes:
- /var/run/docker.sock:/var/run/docker.sock
Now you can launch Kafka locally:
export HOST_IP=$(ifconfig | grep -E "([0-9]{1,3}\.){3}[0-9]{1,3}" | grep -v 127.0.0.1 | awk '{ print $2 }' | cut -f2 -d: | head -n1) && docker-compose up
We’re extracting the HOST_IP here because of how Kafka Docker image works - it creates a bridge network. Both container ports (9092 and 2181) are mapped directly to the host’s network interface, thus needing the IP. More on this here: https://github.com/wurstmeister/kafka-docker/wiki/Connectivity
Step 2 - NPM install
You’ll have to install both kafkajs and express packages. In addition, you’ll need a kafkajs plugin for OpenTelemetry. This plugin was created at Aspecto as part of our ongoing contribution to OpenTelemtry.
The kafkajs plugin captures producer and consumer operations and creates spans according to the semantic conventions for Messaging Systems. You can read more about this plugin here or check it out at the github repo.
Install the following:
npm install kafkajs
npm install express
npm install opentelemetry-plugin-kafkajs
npm install \
@opentelemetry/core \
@opentelemetry/node \
@opentelemetry/plugin-http \
@opentelemetry/plugin-https \
@opentelemetry/plugin-express \
@opentelemetry/metrics \
@opentelemetry/tracing
This is our complete package.json
(Note: the use of node -r is crucial to enable opentelemetry tracing before the app starts. The next section explains about the tracing.js file).
{
"name": "kafka",
"version": "1.0.0",
"description": "",
"main": "app.js",
"scripts": {
"start": "node -r ./tracing.js app.js",
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC",
"dependencies": {
"@opentelemetry/core": "^0.16.0",
"@opentelemetry/exporter-zipkin": "^0.16.0",
"@opentelemetry/metrics": "^0.16.0",
"@opentelemetry/node": "^0.16.0",
"@opentelemetry/plugin-express": "^0.13.0",
"@opentelemetry/plugin-http": "^0.16.0",
"@opentelemetry/plugin-https": "^0.16.0",
"@opentelemetry/tracing": "^0.16.0",
"express": "^4.17.1",
"kafkajs": "^1.15.0",
"opentelemetry-plugin-kafkajs": "^0.2.0"
}
}
Step 3 - app.js file with express
This file exposes a POST endpoint that writes a message to a Kafka topic
"use strict";
const express = require("express");
const PORT = process.env.PORT || "8080";
const { Kafka } = require('kafkajs');
const app = express();
const kafka = new Kafka({
clientId: 'my-app',
brokers: ['localhost:9092']
})
const TOPIC_NAME = 'my-topic';
// this just produces a message to a kafka topic
async function produce() {
const producer = kafka.producer()
await producer.connect()
await producer.send({
topic: TOPIC_NAME,
messages: [
{ key: 'key1', value: 'hello world' },
],
})
}
app.post("/messages", async (req, res) => {
await produce();
res.send("Hello World");
});
app.listen(parseInt(PORT, 10), () => {
console.log(`Listening for requests on http://localhost:${PORT}`);
});
Add a file called tracing.js to enable opentelemtry data collection for our app.
(If you’re feeling lost with all the OpenTelemetry jargon, they have a whole world of glossary you can get yourself familiar with)
By using OpenTelemetry’s NodeTracerProvider, we collect node data with a Kafka plugin that tells opentelemetry to collect Kafka data.
We will now use a Zipkin exporter to export the collected data to Zipkin. Zipkin is an open source tracing system that includes a UI.
'use strict';
const { LogLevel } = require("@opentelemetry/core");
const { NodeTracerProvider } = require("@opentelemetry/node");
const { SimpleSpanProcessor } = require("@opentelemetry/tracing");
const { ZipkinExporter } = require('@opentelemetry/exporter-zipkin');
const options = {
headers: {
'my-header': 'header-value',
},
url: 'http://localhost:9411/api/v2/spans',
serviceName: 'my-app'
}
const zipkinExporter = new ZipkinExporter(options);
const provider = new NodeTracerProvider({
logLevel: LogLevel.ERROR,
plugins: {
kafkajs: {
enabled: true,
path: "opentelemetry-plugin-kafkajs",
},
},
});
provider.register();
provider.addSpanProcessor(new SimpleSpanProcessor(zipkinExporter));
console.log("tracing initialized");
provider.register();
Use docker to run zipkin locally:
docker run -d -p 9411:9411 openzipkin/zipkin
At this point you should have everything set up, including the code, Zipkin & Kafka running.
This code has to run before the app starts, so be sure to run your app like this:
node -r ./tracing.js app.js
Or just use npm start if you took our package.json.
Step 4 - Insights
Open your browser and go to http://localhost:9411/zipkin/
Perform a post request to create a message in the Kafka topic.
curl --location --request POST 'http://localhost:8080/messages'
After that, go back to zipkin to see the data collected (click on Run Query):
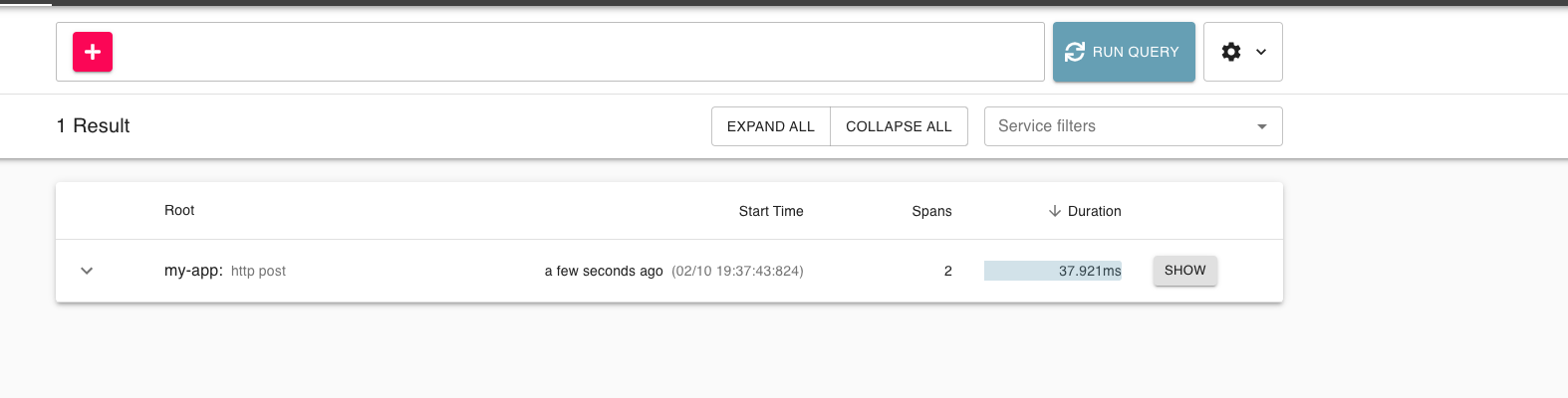
This already gives us some data about what happened (for example, the duration of this request).
Click on “show” :
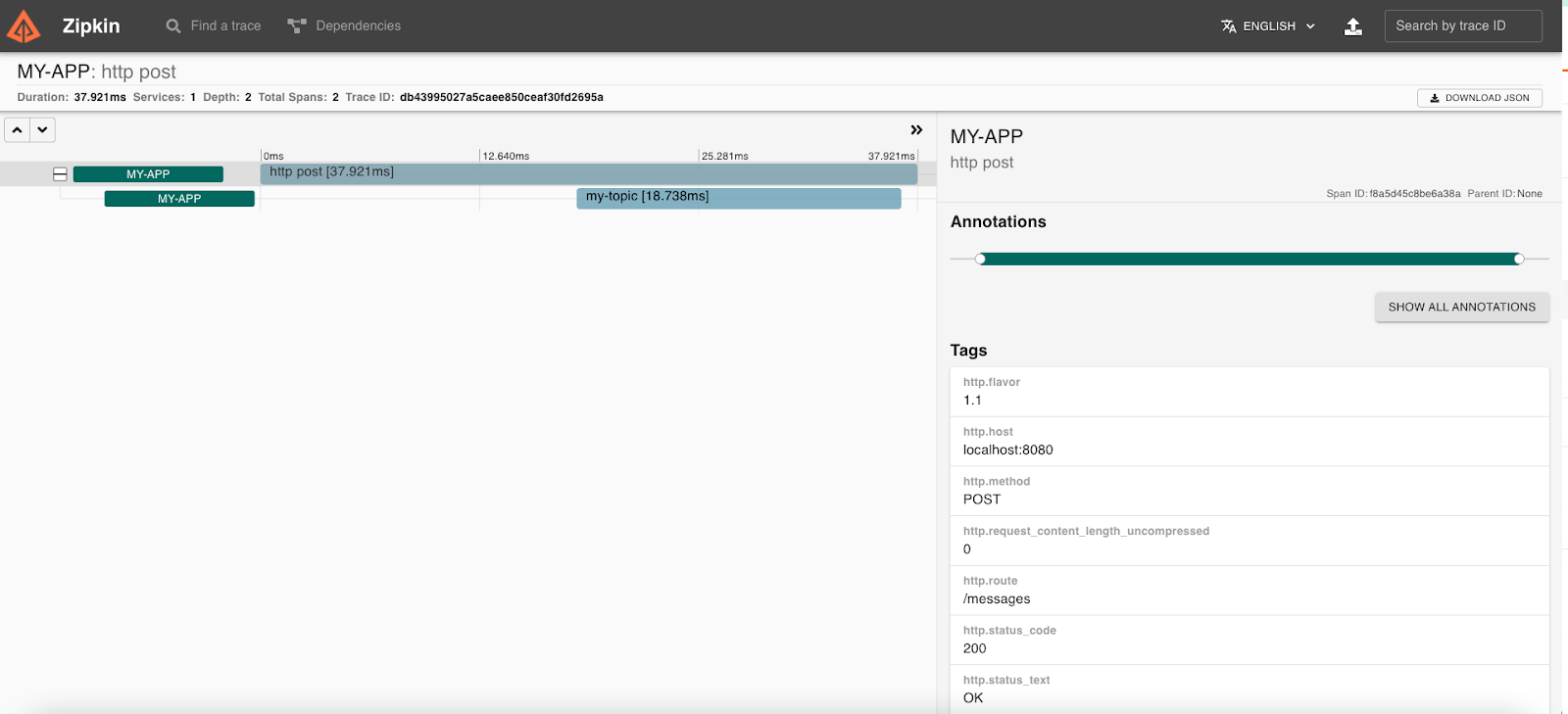
You can see that the whole post request took 37.921ms.
Out of which, something took 18.738ms. Wonder what that is? Click on it to find out.
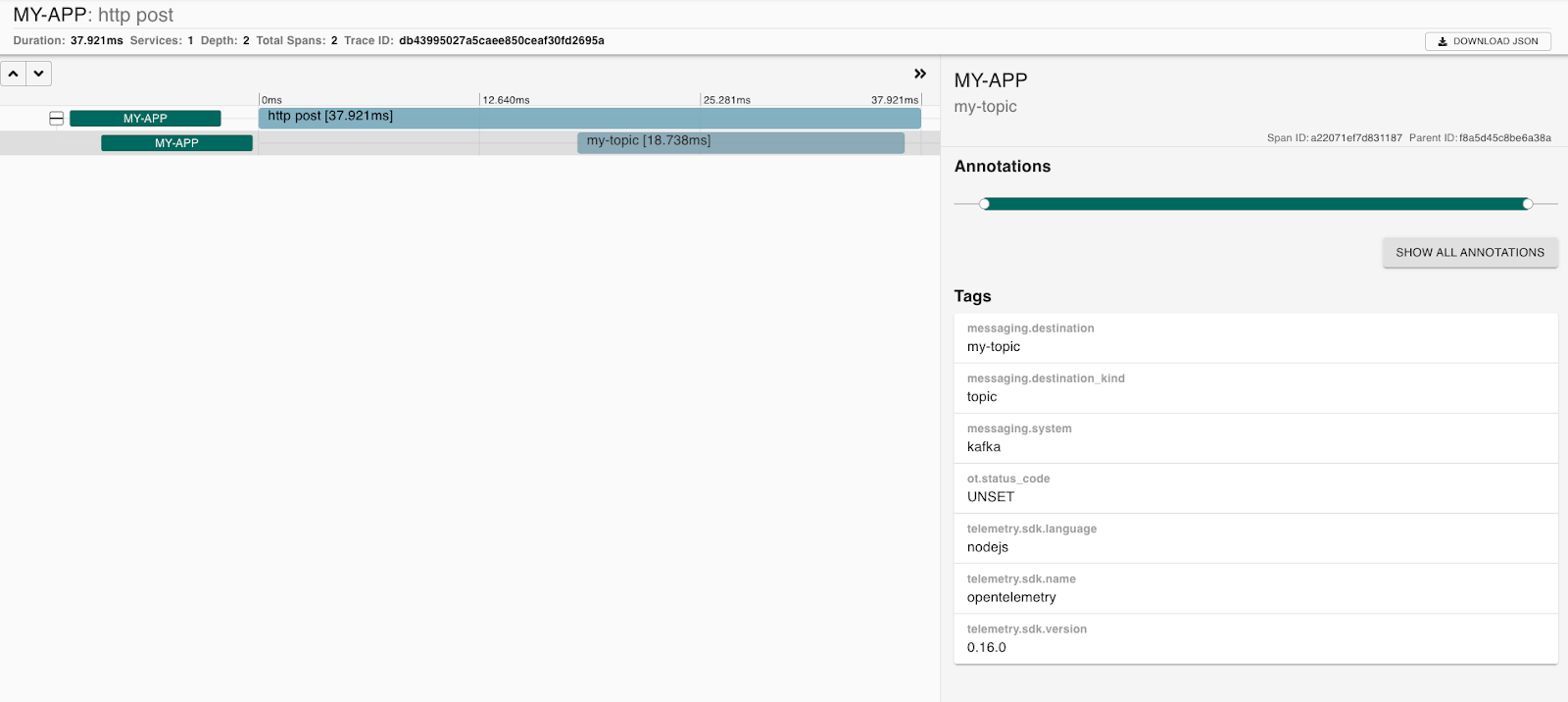
Quite interestingly, we can see that Zipkin shows our Kafka message. You can even see the message destination - my-topic.
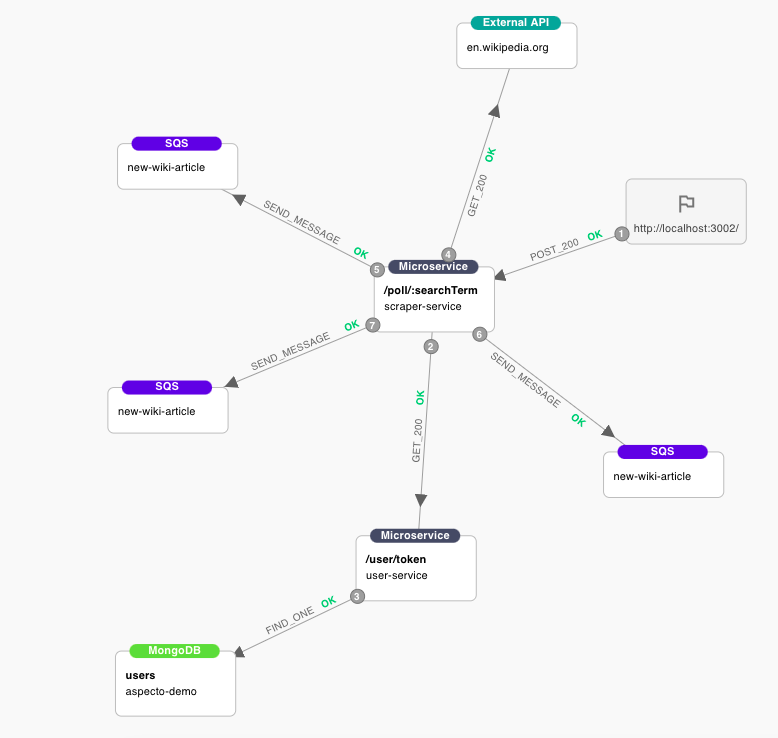
See the full picture
That’s it basically. With relatively no effort, we were able to achieve that desired visibility into async messaging by using OpenTelemetry.
The downside of this setup is that we only zoomed into a specific part of the flow and in reality, you’ll want to see the full journey a single message has gone through.
In addition, your system and services’ communication are so much more complicated, you need to do some heavy-lifting to get that holistic view of your system and deeper level of visibility.
For the time being, I hope we made your life a little bit easier, giving you a quick way to see the paths messages go through so you can make troubleshooting microservices less of a nightmare.
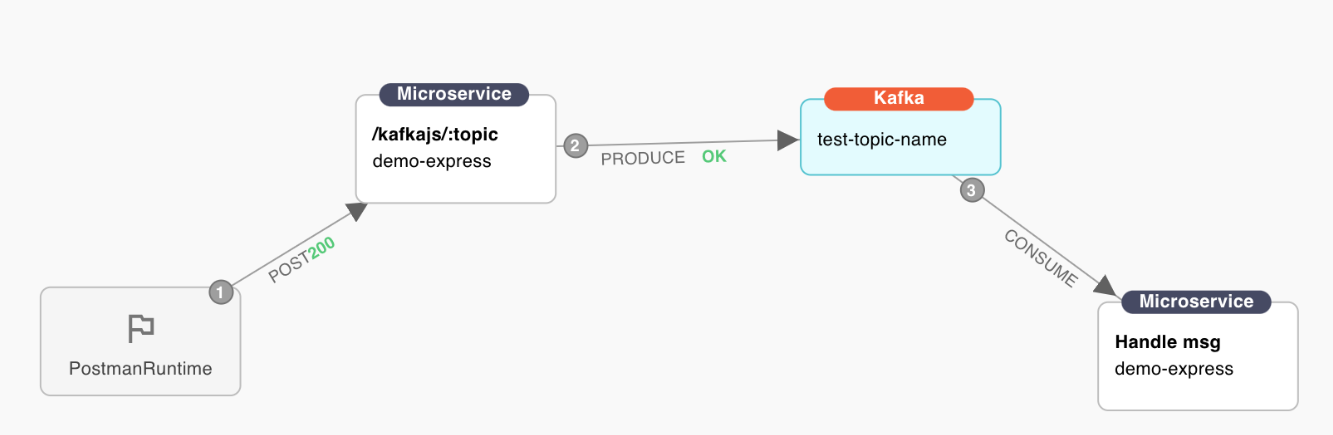
The full journey a single message has gone through.


