
.png)






Hello in this post we'll be looking at some "advanced" features on terminal Git to deal with file changes, branches, commit hand, ling, and shortening repetitive work.
This post is the continuation (aka part 2) of a previous post about ways to do common tasks using terminal Git. You can read that one here.
Additionally, this post is meant to be a standalone one.
You can either check the previous one for context or start from here if you don't want to review the basics.
Well then, without further ado, let's get this one going!

Signing commits
If you ever wondered why some commits that you make on GitHub appear with a "Verified" label and others don't like this...
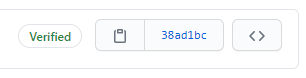
That is because GitHub signs the commit with a verified signature using its own key.
Then every time you make a commit from the GitHub dashboard, you'll get a verified commit.
You can also create verified commits locally before pushing them to the remote.
First, you have to create a GPG key pair that you'll be using to sign the commits locally.
If you have no idea how to do such thing, take a look at this article on the GitHub Docs.
Now, once you have your GPG key pair created and you told GitHub about it.
You can start signing commits by using the "sign" flag (or "-S" for short) with the git commit command like so:
Once you push the commit, you can see it appear in the "commits" tab along with the other commits looking very nicely.
Available options on git reset
Now you might be aware that the 'reset' command in Git is used to undo changes or make things right when we previously messed up.
But there are 3 options we can pass to this command and each one will produce a different result.
Before looking into those options, let's quickly review some of the different states that files can be in Git.
There's the working directory, the staging index and the commit history.
If you create new files in a project, Git will detect them and tell you that you have 'untracked files'.
That is, fileg in the working directoryt have not been added to the _staging area.

If you run the command git reset without passing any options, it would be the same as if you have done.
The other two options are '--soft' and '--hard'. You probably already know what those two are for but in case you need a refresher...
- Mixed is the default option that removes the changes and puts them back into the working directory.
- Soft removes the changes and puts them into the staging area.
- Hard removes the changes but discards them completely so they will no longer be found in the working directory nor the staging area.
Let's see them in action.
Suppose that we create a new file with some changes in it and then commit them.
We would see something like this when checking the commit log.

Before pushing, we realized that we made a mistake with the changes.
So we'll want to discard the commit and have the files ready to be edited again.
If we run git reset --soft it will remove the commit and put the files back in the staging area.
(Don't forget to tell Git what commit you want to reset otherwise the command will have no effect).
If we want to reset the last commit, we would use the expression 'HEAD~1' which means "from the HEAD pointer, take the first commit". Like this...
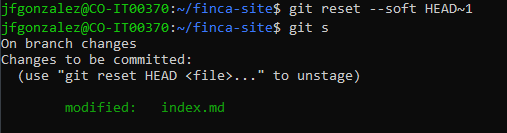
Now, you can see there that Git is saying that you can use git reset HEAD <file> to unstage a file.
That will have the same effect as if you would ran the 'reset' command with the '--mixed' flag instead of the '--soft' flag.
Although just to see the result, let's commit the changes again and run the command with the '--mixed' flag. It would look like this...
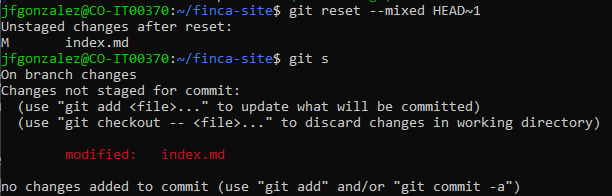
Ahhh so you see that? The changes were undone and the file is now in the working directory. You can also see the extra output that git gave us this time.
Now if for any reason we screwed up something and want to get rid of the commit plus the changes made.
We then run git reset --hard and that will make it as if the changes were never introduced.
Then, if we run the git status command we would have a clean history with a "nothing to commit message".
WARNING: Only use the '--hard' flag when you really want to get rid of a commit and all the changes in it or else it can get you in troubles if you do resets carelessly
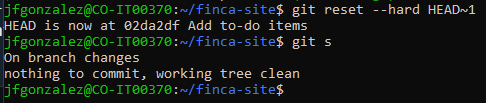
This way, we go back to the initial state we were in before making changes to the files.
We can do other changes, or review other files or do something else entirely.
Recovering from a hard reset
Let's suppose now that you wanted to try the different 'reset' options in a real world scenario.
And then you accidentally deleted some work on a repository of yours (or even from work gulp)
Is that the end? Will you have to make everything again from scratch?

.......
Don't fret my friend, Git got us covered. As long as the changes have been tracked by it, there's a way to get them back.
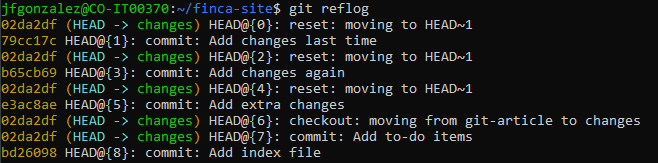
Let's look at the powerful git reflog command.
After the hard reset, remember that the status said 'nothing to commit, working tree clean'.
If we want to bring one of the commits back 'from the dead', we can run the git reflog command and it will show the following.
Now we can do something like this...
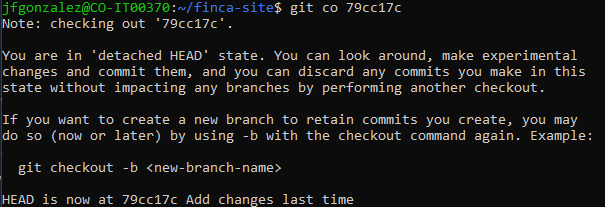
We're now located right at the commit where the changes existed before being wiped out by git reset --hard.
You can also see in the message that we're now in the 'detached HEAD' state where we can look around and play with the files that existed in that point in time.
Remember as well that 'HEAD' is nothing more than a pointer to a commit.
And is now pointing to the commit id we checked out to instead of pointing to where it normally does.
So now, since we wanted to recover the lost changes in index.md.
We can create a new branch to keep those changes followiGit's instruction in the message.
Something like git checkout -b restore-index we'll do the trick.
Now if I check the status and commit log, I'll see the following.
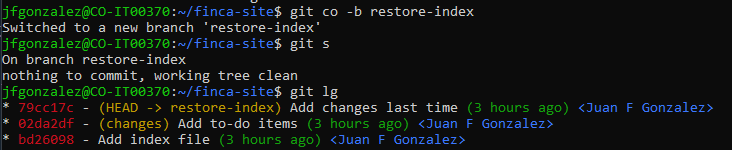
Look at that, isn't it really cool? We were able to recover the previous changes with the commit that had them.
We can now integrate them into the master branch with a git merge if we want to.
Adding files, rewording messages, merging changes and more with just one command
Now let's see how we can take our commit handling skills up a notch.
We can do nifty stuff with git rebase specially with the 'interactive' flag to make it much cooler and easier to use.
When you first run the rebase command with the '--interactive' flag (or '-i' for short) you will see something like this.

The message tells you what you need to know to make it work.
We have to tell Git what branch we want to rebase against (which can be the branch that we were on initially)
If we run that command, the default editor is going to open up and show us the following
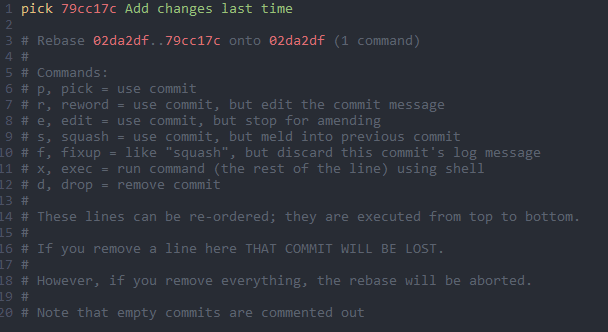
As you can see we'll be rebasing the commit on the 'restore-index' branch onto the 'changes' branch.
By default the commit id and message will appear preceded by the word 'pick'.
This means that is a commit we'll use as part of the rebase.
Below that, you can see what are the other available commands besides 'pick'.
You can also see some more important info about how the rebase works.
If we save the changes and exit the editor, the rebase will be completed.
And we're now back to the terminal with a success message from Git.

We can do much more useful stuff with the interactive mode f than if we were to run the git rebase command alone.
- We can change the commit message of any commit not just the last one with the 'reword' command.
- We can add files or changes that we may have missed in a commit with the 'edit' command.
- We can put together several commits into a more descriptive commit with the 'squash' command.
- We can do the same as before but without caring about the commit message with the 'fixup' command.
- We can remove commits that probably were a bad idea and don't want any peer reviewers to see them with the 'drop' command.
And on and on all with the power of just one Git command.
Automating the rebase process with 'autosquash'
What's even cooler is that you can automate this process once you start using rebase more often and avoid having to do extra work on the Git editor.
Let's look an example of that.
Instead of making incremental progress on several commits and then when we're done.
- Pull up the git editor.
- Choose the commits to squash.
- Choose the message to leave on the commit.
- Make sure everything is in order.
We can tell Git upfront to do all of that.
Assume we made some extra changes on the index.md file that we had and now we're going to commit those new changes.
We would add the changes and then create a commit as normal with a message of what we're working on.

Now for the next commits, instead of writing random messages and discard them at the end, we can use the '--fixup' flag and the id of the commit that we'll rebase into like so...

Now, if we inspect the commit log we'll see the following.

That 'fixup!' at the beginning tells what is the intention of the commit and what commit those changes belong to.
Next time we make some changes and are going to commit them.
We can avoid passing the id of the first commit (maybe because we didn't copied it and we forgot what it was) by doing the following.
That may look strange but is just a way to tell Git "find the most recent commit with the string 'important' in its commit message"
And we can repeat that for all the 'WIP' commits we're going to make, they don't even need to be in order.
Suppose I had to work on a different feature while I was on the 'index.md' file. At the end I could have a commit log like this...

You can see that the 'fixups' are non sequential and there's a commit for another change that needed to be done.
The only thing that we need to do now is to make a rebase using the '--autosquash' flag with the commit id or the name of the branch we're rebasing into.
That will launch the editor and you can see that the commits are already properly ordered with the command that we want.
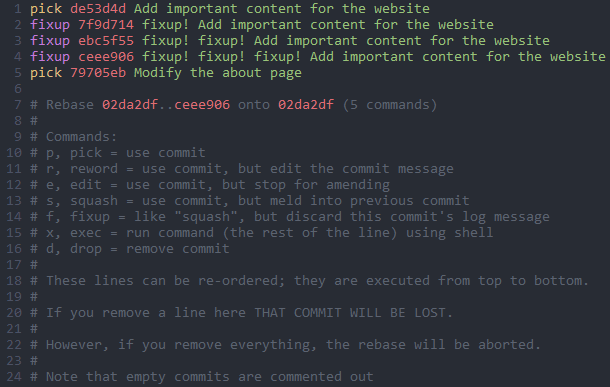
We can now save and exit the editor and the rebase will complete successfully. If for any reason you see something wrong or missing there, remove the lines above the comments and quit the editor.
Now, when we inspect the commit log we'll see something like

So the 'fixups' got squashed into the original commit we designated for that purpose.
Also, the other commit was properly moved and we didn't have to do anything extra on the editor for all of that to happen!
Force pushing to the remote with caution
Now it's Important to note that the act of rebasing rewrites the history and changes the id's of the affected commits.
With it you will have a different history than the remote because the commits will be different even if the changes are the same.
Since we rewrote the history by rebasing, you may think is ok to just do a force push to the remote.
That way it will have the same history that we have locally. But instead of doing this...
We'll be making a push with the '--force-with-lease' flag instead of the '--force' flag like this.
That is an option that will take extra caution before making the push.
It will fail the operation if someone else added other commits to that branch (essentially making sure you don't overwrite a team member's work)
Saving time on repetitive stuff using aliases. Once you get used to a certain git workflow that gets repeated several times a day, you can optimize it using aliases in Git.
Those go in the .gitconfig file in the [alias] section and they essentially allow us to create 'new' commands if we want to.
You probably already noticed in the examples above that I have very minimalist aliases for my most used commands 😅
You can either take a command with its options and create a more descriptive command like
or you can run a long command with a few keys like
That's the beauty of aliases, you can customize Git however you want. "The only limit is your own imagination".
Refer to the documentation in the Git book for more on aliases.
Wrapping up
Now with this knowledge you're ready to go out and slay some workflow dragons and more importantly have the confidence to use Git to do what for others would look like terminal wizardry.
Remember to use your powers for good not only to improve your workflow but also to help others that are not that well-versed in the arcane arts of Git like you are 🧙♂️
That's it for this post! Thanks for reading so far I hope it was insightful and gave you some ideas on how to use Git in a better and more efficient way from now on.




