
ReAct loops, LangChain chains, CrewAI role orchestration, iteration limits, cost ceilings — what it takes to ship agents to production in 2026.
Walk into a production codebase in 2026 and you'll find AI agents wired into deploys, on-call triage, customer-support flows — places engineers would've reached for a Lambda or a queue worker a year ago. The substitution happened quietly: where you used to write deterministic logic, you now hand the problem to an agent and let it plan, call tools, and self-correct via the ReAct loop. LangChain and CrewAI are the two frameworks most teams reach for first, and Google DeepMind's SIMA generalist agent hints at what a less-specialized agent might look like a year from now.
What this guide covers:
- Single-agent vs multi-agent — the architectural decision that determines most of your downstream pain. Single-agent is right for ~80% of cases; the trap is reaching for multi-agent because it sounds more capable.
- LangChain primitives — chains, agents, tools, memory. The full stack of building blocks.
- CrewAI for role-based orchestration — when single-agent genuinely isn't enough and you need specialized agents collaborating.
- Production cost, latency, and guardrails — the part of the stack that breaks first when you scale from prototype to prod.
- What's coming next — MCP, agent marketplaces, and the LangGraph / AutoGen alternatives.
Two things to internalize before reading further. First, agents fail more often than chatbots, and they fail expensively — most production agent bugs come from runaway loops (an agent that won't stop calling itself), tools that get retried until something OOMs, or context that grows linearly until the model's window silently truncates. Second, iteration limits, cost ceilings, and clear termination conditions aren't optional polish — they're the part of the stack that turns a demo into something on-call won't get paged about at 3 AM.
Langchain Tutorial For Beginners (2026 Guide) | AI Agents For Data Engineers
Single-Agent vs Multi-Agent Architecture Patterns
Choosing between a single-agent or multi-agent architecture is a critical decision when building production-ready AI agents. The right choice depends largely on the complexity of the task - whether it’s straightforward or requires multiple specialized roles working together.
Single-Agent Systems: Streamlined for Simplicity
A single-agent system relies on one LLM to handle a goal, select 3–5 essential AI tools for developers, and operate within a ReAct loop until the task is completed. These systems are ideal for straightforward tasks where one "brain" can handle the workload. A great example is customer support bots, which can query order databases, check inventory, and process refunds - all without the need for collaboration among multiple agents.
This approach comes with several advantages: fewer components to manage, easier debugging, and quicker response times. However, these systems have limitations. When tasked with managing more than 5 tools, their reliability can drop. Each additional tool increases the complexity, so sticking to a small, focused set of tools is recommended.
For more intricate workflows, multi-agent systems offer a better solution.
Multi-Agent Systems: Built for Complexity
Multi-agent systems (MAS) divide tasks among specialized agents. For instance, one agent might act as a Researcher to gather information, another as a Coder to write scripts, and a third as a Reviewer to verify results. Each agent is assigned a specific role and toolset, making these systems well-suited for handling complex workflows with greater reliability.
MAS often employ patterns such as the Coordinator (delegating tasks), Pipeline (sequential processing), and Debate (mutual critique) to ensure quality. For example, in a content creation pipeline, one agent might research and outline a topic, another drafts the content, and a third edits for clarity and tone.
The downside? Multi-agent systems come with higher costs and longer processing times. Each additional agent adds to the expense; a complex 20-step task could cost between $1 and $5 per execution. To manage costs, developers often use more economical models for intermediate steps while reserving high-performance models for critical reasoning. Interestingly, a McKinsey survey from January 2026 noted that 57% of organizations with AI programs had implemented at least one agentic system in production.
Feature
Single-Agent System
Multi-Agent System
Complexity
Low; single LLM loop
High; requires orchestration
Cost
Lower (fewer LLM calls)
Higher (multiple calls per task)
Best For
Simple tasks, retrieval-augmented generation, single-step actions
Research, coding, and complex content pipelines
Tool Management
Limited to 3–5 tools to avoid confusion
Tools distributed across specialized agents
Debugging
Simpler debugging
More challenging due to orchestration
Next, we’ll dive into frameworks like LangChain that are designed to maximize the performance of these architectures.
LangChain Deep Dive: Chains, Agents, Tools, and Memory
LangChain has quickly become a go-to framework for developers building AI agents. Its key components - chains, agents, tools, and memory - are the foundation for creating systems that can interact with external data and maintain context during conversations.
How Chains and Agents Work
To effectively use LangChain, it's important to understand how chains differ from agents. Chains are essentially predefined sequences of steps involving LLM calls and data transformations. Think of them as scripts: you define the process, and the system follows it step by step. They work best for tasks with predictable outcomes, like summarizing a document or generating product descriptions from structured inputs.
Agents, on the other hand, operate dynamically. Instead of following a fixed script, they rely on an LLM to make decisions in real time, using a ReAct loop to determine the next step until they achieve their goal. For instance, if someone asks, "What's the status of my order and when will it arrive?", an agent might first query an order database, then access a shipping API, and finally combine the results into a coherent answer.
"A chatbot responds to a prompt. An AI agent pursues a goal." - Global Publicist 24
The reasoning capabilities of the LLM are critical for agents. Developers often pair high-reasoning models, like GPT-4o or Claude 3.5 Sonnet, for decision-making with more cost-effective models for simpler tasks like data retrieval.
To avoid runaway processes, always set iteration limits. Use the max_iterations parameter (commonly set between 5–7) in the AgentExecutor to prevent infinite loops, which can quickly drain your API budget. Without this safeguard, an agent might repeatedly call the same tool in error.
Tools and Memory: Extending Agent Capabilities
Tools enable agents to interact with external systems like APIs or databases. The LLM decides when to use these tools based on the descriptions you provide. For example, a tool labeled "Search customer orders by order ID; returns status, items, and shipping info" provides clear guidance for the agent.
Start small with 3–5 tools to keep the system manageable. Overloading an agent with too many options (e.g., 50+ tools) can confuse it and lower its reliability. For larger toolsets, embedding-based retrieval can help by narrowing down to the top 5 most relevant tools for a query.
Memory is what elevates an agent from being a simple chatbot to becoming context-aware. LangChain offers three types of memory:
- In-context memory: Temporary storage for recent conversation history.
- External memory: Long-term storage in vector databases like Chroma or Pinecone.
- Episodic memory: Logs of past runs to improve future performance.
In production systems, memory is typically scoped across three levels: user_id (for user-specific preferences), run_id (for session-specific context), and agent_id (for shared knowledge across users). To avoid exceeding token limits (e.g., 200,000 tokens for Claude), you can use ConversationBufferWindowMemory to keep only the last 10 exchanges or ConversationSummaryBufferMemory to summarize older interactions automatically.
"Memory matters more than you think. Without persistent memory, your agent forgets user context between sessions. Users hate repeating themselves." - CowrieDev, Developer, Bswen
For production use, memory and tools directly impact cost and efficiency. A LangChain agent using three tools and Retrieval-Augmented Generation (RAG) typically costs $0.02–$0.08 per conversation in API fees. For a support agent handling 500 conversations daily, this translates to $10–$40 per day, or around $300–$1,200 per month. Implementing Redis to cache results from expensive tools or repeated queries can help reduce both latency and costs.
These components not only expand the agent's capabilities but also play a key role in optimizing performance and managing expenses.
CrewAI: Role-Based Multi-Agent Orchestration
CrewAI takes a team-oriented approach to AI agent management, offering a fresh perspective compared to LangChain's focus on individual agents. While LangChain gives you precise control over each agent, CrewAI organizes agents as a coordinated team, with each member assigned a specific role and responsibility. You define the roles, and CrewAI manages the coordination.
At its core, CrewAI revolves around four main components: Agents (the workers), Tasks (the individual pieces of work), Tools (the capabilities available to agents), and the Crew (the orchestration engine). Each agent is assigned a role, a goal, and a backstory, which helps establish its tone and purpose. This structured setup enables multiple agents to collaborate effectively on complex workflows, avoiding conflicts or redundancy.
"CrewAI is built for production, not demos. It prioritizes reliability, observability, and cost control." - Adrien Payong and Shaoni Mukherjee
The framework supports two execution patterns: Sequential and Hierarchical. Sequential execution is ideal for linear workflows, such as research → write → review. On the other hand, Hierarchical execution involves a manager agent dynamically delegating tasks to specialists, making it better suited for workflows that require flexibility and adaptive problem-solving.
Role Assignment and Task Coordination
CrewAI’s role-based system relies on its "Role-Goal-Backstory" framework to define agents. Instead of cramming all instructions into a single prompt, agents are given explicit roles with clear goals. For instance, a Researcher agent might have the goal "Identify the latest trends in AI agent frameworks", paired with a backstory like "You are a tech journalist with 10 years of experience covering developer tools." This added context helps the AI maintain consistency and produce more relevant, high-quality results.
Tasks are defined separately, with attributes such as description, expected_output, and an assigned agent. CrewAI’s orchestration engine links tasks using a context attribute, automatically passing the output of one task as input to the next. This feature distinguishes CrewAI from LangChain, which relies on memory management to handle similar workflows. The result is a streamlined process where data flows seamlessly between tasks without manual intervention.
To maintain control, you can set limits like max_iter (default is 15) and max_execution_time to prevent infinite loops or excessive runtime. Additionally, you can disable delegation (allow_delegation=False) to avoid agents endlessly assigning tasks back and forth.
Cost efficiency is another strength of CrewAI. A typical three-agent sequential crew using GPT-4o costs approximately $0.10–$0.20 per run, while opting for GPT-4o-mini for simpler tasks can lower costs to $0.06–$0.12. For a system handling 1,000 runs per month, this translates to a cost range of $100 to $200, depending on the chosen configuration.
CrewAI also simplifies configuration through YAML files. By separating configuration from code, non-developers can easily adjust roles and prompts without diving into Python. This approach also ensures the system remains easier to manage as it scales.
Next, we’ll look at how CrewAI stacks up against other frameworks to refine your strategy for implementing AI agents.
Comparing Frameworks: AutoGen, LangGraph, and Others
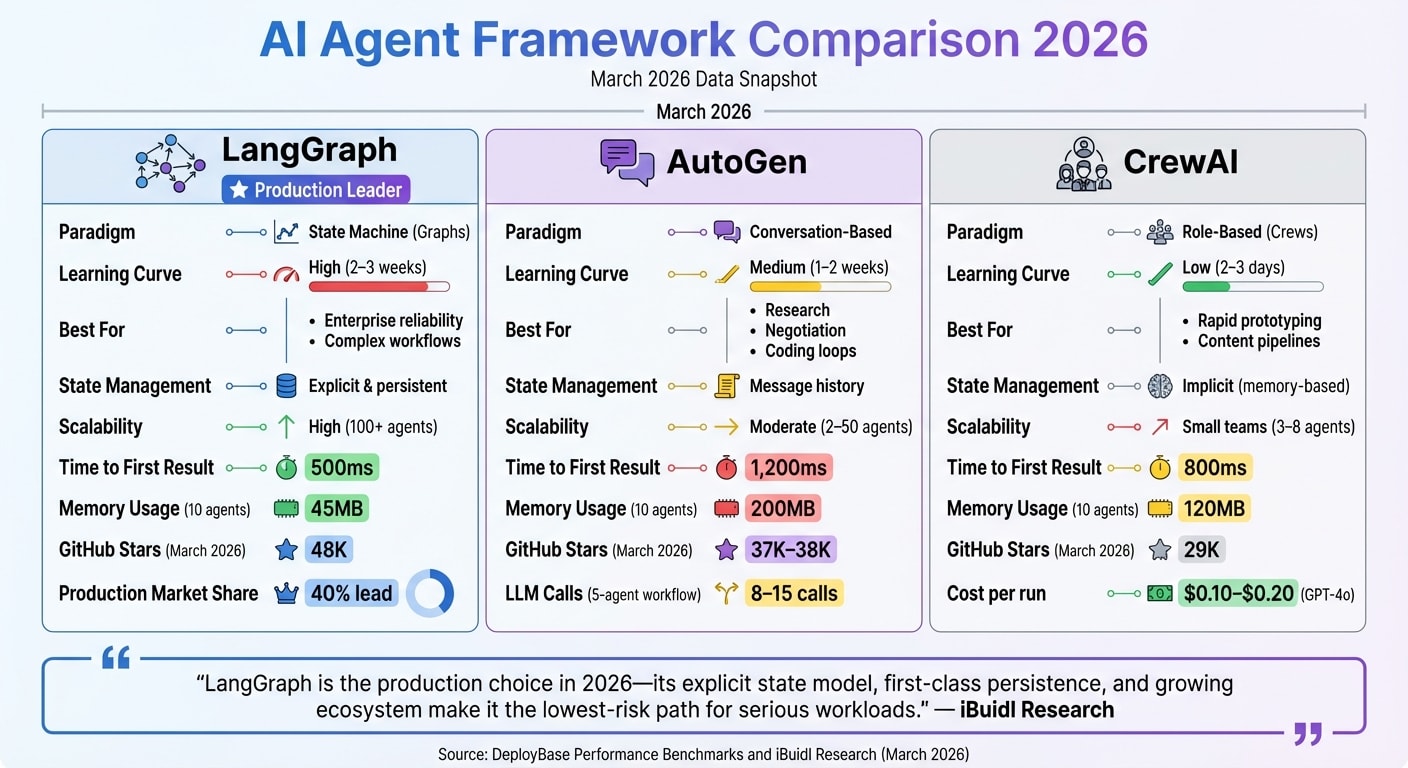
AI Agent Framework Comparison: LangGraph vs AutoGen vs CrewAI
For developers working on AI agents in 2026, understanding the strengths and trade-offs of various frameworks is key. Let’s break down how LangGraph, AutoGen, and others stack up, especially in comparison to CrewAI's team-based approach.
LangGraph employs a directed graph architecture, where nodes represent functions and edges define state transitions. Essentially, it operates as a state machine, offering precise control and persistent state management. This makes it a go-to for handling complex, long-running workflows. By March 2026, LangGraph led in production deployments, holding a 40% edge over competing frameworks.
AutoGen, created by Microsoft, focuses on a conversation-driven model. Here, agents interact autonomously through message-passing. Unlike LangGraph’s rigid workflows, AutoGen agents collaborate, negotiate, and adapt dynamically, making it a great fit for research automation and iterative tasks like code generation. The January 2026 v0.4 update introduced an asynchronous, event-driven architecture, enabling hundreds of concurrent agent conversations without bottlenecks. However, this flexibility comes at a cost - AutoGen typically requires 8–15 LLM calls for a standard 5-agent workflow, compared to LangGraph’s 5–8 calls.
"LangGraph is the production choice in 2026 - its explicit state model, first-class persistence, and growing ecosystem... make it the lowest-risk path for serious workloads." - iBuidl Research
As mentioned earlier, CrewAI is often used for prototyping before transitioning to LangGraph for production. This approach leverages CrewAI’s speed and simplicity early on while benefiting from LangGraph’s observability and scalability for production workloads. However, it’s important to avoid mixing frameworks within a single production domain, as this can lead to operational headaches and fragmented monitoring. This framework ecosystem highlights how developers can align tools with specific project phases, from rapid prototyping to scalable, production-ready systems.
Framework Comparison Table
Feature
LangGraph
AutoGen
CrewAI
Paradigm
State Machine (Graphs)
Conversation-Based
Role-Based (Crews)
Learning Curve
High (2–3 weeks)
Medium (1–2 weeks)
Low (2–3 days)
Best For
Enterprise reliability, complex workflows
Research, negotiation, coding loops
Rapid prototyping, content pipelines
State Management
Explicit & persistent
Message history
Implicit (memory-based)
Scalability
High (100+ agents)
Moderate (2–50 agents)
Small teams (3–8 agents)
Time to First Result
500ms
1,200ms
800ms
Memory Usage (10 agents)
45MB
200MB
120MB
GitHub Stars (March 2026)
48K
37K–38K
29K
Source: DeployBase Performance Benchmarks and iBuidl Research (March 2026)
For workflows requiring strict type safety and validated outputs, Pydantic AI has gained traction as a specialized framework. In a 90-day evaluation, it scored 8/10 for developer experience compared to LangChain’s 5/10. On the other hand, if your workflow is straightforward and only involves 2–3 tools in a linear setup, frameworks might not be necessary. Simple SDKs from providers like OpenAI or Vercel can get the job done without adding unnecessary complexity.
Step-by-Step Tutorial: Building Your First AI Agent
In this tutorial, we’ll create a research assistant agent that can search the web and summarize its findings. The process uses CrewAI, a framework that allows you to set up a 3-agent pipeline with fewer than 100 lines of Python code. To get started, you’ll need Python 3.11+, an OpenAI API key, and a Serper API key for web searches.
Setup and Installation
First, make sure to set up a virtual environment to avoid any conflicts with Pydantic. Once that’s done, install the required packages:
pip install crewai crewai-tools
For better debugging, set the environment variable LANGSMITH_TRACING=true. This will enable observability, helping you trace and debug each step in the agent’s reasoning process.
Defining Your Agent
When defining your agent, focus on three key elements: its role, goal, and backstory. The backstory is especially important because it influences how the agent approaches tasks. After defining these, you’ll need to create tools using the @tool decorator. This decorator ensures the tools are properly interpreted by the framework.
Each tool should include:
- A description: Clearly explain what the tool does.
- An expected_output: Specify the exact format the response should follow.
“The key is always in the wrapper: simplify the interface and write a crystal-clear description so the agent knows when to use its new superpower.” - Abdul Rehman Khan, Founder, Dev Tech Insights
Setting Guardrails
To keep your agent efficient and cost-effective, set guardrails right away. For example:
- Use
max_iterations=7to prevent infinite loops. - Set a 30-second timeout to manage API costs.
- Enable
verbose=Trueto monitor the agent’s reasoning in real time.
Running an agent with GPT-4o typically costs between $0.10 and $0.20. For less critical tasks, you can save by using GPT-4o-mini, which reduces the cost to $0.06–$0.12.
Testing and Refining
Start with 3–5 tools. Adding more than this can overwhelm the agent. Test your agent with simple queries to ensure it selects the correct tool and avoids infinite loops. If issues arise, refine the tool descriptions or use a try/except block for each tool to handle errors gracefully.
For example, instead of a vague prompt like “Search database,” use something more precise: “Search customer orders by order ID; returns status, items, and shipping info.”
Once your agent is working as intended, the next step is to address production concerns like cost management, latency, and error handling.
Production Considerations: Cost, Latency, Error Handling, and Guardrails
When deploying production-ready agents, managing costs, reducing latency, ensuring error handling, and setting up safety guardrails are non-negotiable. Unlike basic chatbots that make a single API call for each interaction, agents operate in loops - each reasoning step, tool invocation, and observation adds another LLM request. This iterative nature can significantly increase expenses.
One of the biggest surprises for developers is the iteration multiplier. Each cycle of the ReAct pattern (reasoning, action, observation) triggers a new API call. For example, a 20-step task using Claude Opus could cost anywhere from $1 to $5 per execution. To keep costs manageable, set limits like MAX_TOKENS_PER_TASK and MAX_TOOL_CALLS. Additionally, routing tasks to the right models can make a big difference. Use higher-cost models like GPT-4 or Claude Opus for tasks requiring complex reasoning or planning, while reserving simpler tasks, such as summarization or execution, for more affordable options like GPT-3.5 or Claude Haiku.
Reducing Latency
To optimize latency, asynchronous frameworks like AutoGen 0.4 (launched in January 2026) are essential for handling multiple agent conversations simultaneously without bottlenecks. Caching can also prevent redundant LLM calls, saving both time and resources. If your agent uses multiple tools, embedding retrieval can help by narrowing down to the five most relevant options, cutting down prompt size and processing time.
Handling Errors
Error handling for agents is a different beast compared to traditional software. As DeepYard aptly put it:
"Agents fail in unpredictable ways. You need observability... At minimum, log every LLM call, tool invocation, and result".
To mitigate risks, set up manual approvals for critical or high-cost actions. For instance, require human intervention for any refund exceeding $100. These practices align with earlier advice on building efficient agents, ensuring both cost control and reliability.
Token Costs and Provider Comparisons
Analyzing token costs provides a clearer picture of production expenses, helping you plan budgets effectively. Here's a breakdown of typical agent task costs as of April 2026:
Agent Task Complexity
Estimated Cost (USD)
Typical Model Usage
Average Latency
Simple (Single tool, 1–3 steps)
$0.01–$0.10
GPT-3.5, Claude Haiku, Gemini Flash
2–4 seconds
Moderate (Multi-tool, 5–10 steps)
$0.20–$0.75
GPT-4o, Claude Sonnet
8–15 seconds
Complex (High reasoning, 20+ steps)
$1.00–$5.00
Claude Opus, GPT-5
30–90 seconds
To identify areas for optimization, use tracing tools like LangSmith, Langfuse, or Braintrust to log every LLM call, tool invocation, and result. This visibility helps pinpoint which steps are consuming the most tokens. Some developers are even sidestepping token costs entirely by deploying local models like Llama 3 through Ollama for their production agents.
When Not to Use Agents: Simpler Alternatives
Not every problem demands the complexity of an agent-based solution. In fact, many so-called "agent problems" are better addressed with straightforward automation. According to production teams, agents operate effectively about 80% of the time, leaving a reliability gap that's unacceptable for critical workflows. As DeepYard succinctly put it:
"Don't build a multi-agent system when a single agent with good tools will do. Start simple, add complexity only when you hit real limitations".
For tasks that require absolute reliability, such as payroll processing or database migrations, deterministic automation is the better choice. For example, a single LLM call using PydanticAI can extract data for just a few cents while ensuring structured output. On the other hand, a 20-step agent loop using a high-end model can cost anywhere from $1 to $5 per run. Similarly, classification tasks achieve high accuracy with a single prompt, avoiding unnecessary delays.
Task
Use This Instead
Why Skip the Agent?
Email forwarding with keywords
Simple automation (Zapier, Make)
Keyword matching doesn’t need interpretation
Data extraction pipelines
Single LLM call + PydanticAI
Faster, cheaper, and ensures type-safe outputs
Performance-critical APIs
Direct LLM API call
Avoids framework overhead and reduces latency
Deleting files or sending emails
Human-in-the-loop script
Prevents catastrophic autonomous errors
These examples highlight how simpler automation can outperform more complex agent loops. Overloading an agent with 50+ tools often backfires, as it struggles to decide which tool to use. When only 3–5 tools are required, a simple chain is more effective than a multi-agent system. In fact, every extra tool you add reduces an agent's reliability.
The takeaway? Start with the simplest solution, like a single prompt or a basic script. Only consider upgrading to an agent-based system when simpler methods can no longer meet your reliability or performance needs.
The Future of AI Agents: Marketplaces and MCP Protocols
The way developers integrate tools and services is evolving. Instead of relying on hardcoded connections, the focus is shifting toward dynamic discovery. At the heart of this transformation is the Model Context Protocol (MCP), which functions like a universal connector - similar to USB-C, but for AI. With MCP, developers only need to implement the protocol once, enabling their agents to connect seamlessly to any compatible service. By January 2026, the MCP ecosystem had grown significantly, boasting over 1,000 servers and 97 million monthly downloads of the MCP SDK.
"MCP transforms AI integration from M models * N tools to M+N connections, dramatically simplifying the ecosystem."
- DigitalApplied
This shift is paving the way for a new agent-to-agent economy, where orchestrator agents can autonomously purchase specialized services using micropayments. For instance, translation services might cost 10 sats per paragraph, web searches 50 sats, and code reviews anywhere from 200 to 500 sats. This setup enables agents to create temporary, task-specific teams without human involvement. The emerging protocol stack supports this economy with MCP for discovery, A2A for messaging, ACP for negotiation, and L402/x402 for handling financial transactions.
Platforms like Agentverse are taking this concept further by introducing tokenized reputation. Agents can issue tradable ERC-20 tokens on bonding curves, with token prices acting as real-time indicators of their reputation. Developers are also enhancing "Agent READMEs" with semantic search capabilities to improve visibility. The market for AI agent systems is expected to grow rapidly, reaching $8.5 billion by 2026 and $35 billion by 2030.
As this ecosystem expands, security remains a critical concern. Research presented at the RSA Conference 2026 revealed that 22% of MCP servers had path traversal vulnerabilities. Additionally, fewer than 4% of MCP-related submissions focused on potential opportunities rather than security risks. To address these issues, the protocol moved under the Linux Foundation's Agentic AI Foundation in December 2025, ensuring neutral governance and collaboration among major industry players.
For developers, these advancements highlight actionable priorities:
- Enhance discoverability by creating semantically rich documentation.
- Apply least privilege principles, granting agents access only to necessary tools.
- Thoroughly validate all inputs to MCP-connected tools.
The future of AI development lies in collaboration, not isolation. Instead of building every tool from scratch, developers can integrate with a growing network of specialized agents and services through standardized protocols. To dive deeper into MCP, check out our Model Context Protocol guide.
Conclusion
The actually load-bearing advice after a year of running agents in production:
Pick by your timeline, not by features. CrewAI is the fastest path to a working multi-agent prototype — a research-and-writing pipeline ships in under 100 lines of Python. LangGraph trades that speed for state management, checkpointing, and the precision you need when an agent sits on the critical path of a customer-facing flow. AutoGen sits in between, optimized for problem-solving via conversational back-and-forth between agents. The framework choice matters less than shipping one and learning how it breaks in your specific environment.
Reliability is where the bill comes due. Token expiration, rate limits, third-party API changes, and provider-specific quirks (Anthropic returning a different error shape than OpenAI for the same condition) will surprise you eventually. Build for them on day one: max_iterations limits, observability via LangSmith or equivalent, human-in-the-loop for irreversible actions, and cost budgets that abort runs before the bill gets interesting.
Cost-tier per step. Use the frontier model only where the reasoning genuinely demands it. Routing and tool-call construction are fine with Haiku, Gemini Flash, or gpt-4o-mini. A two-tier setup typically cuts production agent costs 50-70% without measurable quality loss on the user-facing output.
Start with 3-5 tools, not 30. Tool sprawl is the most common cause of agent decision paralysis. Each tool added increases the prompt size and the surface area for misuse. Resist the temptation to expose the whole SDK — give the agent the four endpoints the workflow actually needs.
Specialize when generic agents stall. For browser-driven workflows, purpose-built tools like Harpa AI handle DOM interaction more reliably than a generic LangChain setup. Same logic applies to code agents, customer-support agents, and any vertical with mature tooling — don't reinvent the agent when a specialized one already exists.
MCP, agent marketplaces, and tokenized reputation systems are interesting and almost certainly the long-term shape of this space. None of that helps if your current agent dies in production on day three. Ship the boring version first. The agent-driven economy is already here - start creating today.
FAQs
How do I choose single-agent vs multi-agent?
Default to single-agent. It's faster, cheaper, easier to debug, and handles the long tail of business workflows just fine. Reach for multi-agent only when you have a genuine reason — typically one of three: (1) parallel work that needs to happen simultaneously, (2) specialized roles where the same prompt for everything would fail (researcher vs reviewer vs executor), or (3) tool sets so large that giving one agent access to all of them produces decision paralysis. If you're unsure which case you're in, you're probably in single-agent territory.
What are the best guardrails to prevent runaway loops?
Three guardrails handle ~95% of runaway scenarios:
- Hard iteration limit. Set a maximum step count (10-50 depending on task complexity) before the agent must terminate. Catches the most common failure mode: an agent stuck in a tool-call → reflect → tool-call cycle.
- Token or cost budget. A dollar-cap or token-cap per agent invocation. Stops the rare but expensive case where an agent's context grows linearly while it "thinks."
- Stall detection. If the agent makes N consecutive calls without changing state (same tool, same arguments), abort. Catches semantic loops the iteration limit alone might miss.
None of these are sophisticated — they're all just if/raise statements wrapped around the agent loop. But they're what separates a demo from production.
How do I estimate and reduce agent costs in production?
Three levers, ordered by impact:
- Context size. Most agent cost is paid on the input side, not output. Audit what you're putting in the prompt — system prompts, conversation history, retrieved docs — and trim aggressively. A 50% input-token reduction is common on a first pass.
- Model selection per step. Not every agent step needs the most capable model. Use a smaller, cheaper model for routing and tool-call construction; reserve the frontier model for the actual reasoning step. Claude Haiku, Gemini Flash, and gpt-4o-mini are all reasonable cheap-tier defaults for non-critical steps.
- Caching. If you're hitting the same RAG index, the same tool, or even the same system prompt across many invocations, cache it. Prompt caching alone can drop a high-volume agent's bill by 40-60%.
Monitor token consumption per invocation in production. Anomaly-spike alerts catch the cases where the iteration limit didn't fire fast enough.
Related Blog Posts
- Can Microsoft AutoDev compete with Devin?
- How to choose the right AI for me as a developer
- Navigating AI for developers
- The Complete Guide to AI Agents for Developers: LangChain, CrewAI, and Beyond
{"@context":"https://schema.org","@type":"FAQPage","mainEntity":\[{"@type":"Question","name":"How do I choose single-agent vs multi-agent?","acceptedAnswer":{"@type":"Answer","text":"
When deciding between single-agent and multi-agent systems, it all comes down to the complexity of your task and what you need to accomplish.
A single-agent system works best for straightforward workflows. If your task can be handled with a well-crafted prompt and a few tools, this option is efficient and gets the job done.
On the other hand, a multi-agent system is better suited for more demanding tasks. It shines when you need to manage context, execute processes in parallel, or use multiple tools. These setups are great for handling intricate workflows, managing domain-specific knowledge, and dealing with tasks that require sequential steps, giving you more flexibility in tackling complex challenges.
"}},{"@type":"Question","name":"What are the best guardrails to prevent runaway loops?","acceptedAnswer":{"@type":"Answer","text":"To keep AI agents from getting stuck in endless loops or consuming too many resources, it's smart to use a mix of strategies. These include setting a token or cost limit, which caps how much processing power or data the agent can use, and stall detection, which spots when the agent stops making progress. Another important step is to define clear termination conditions, so the agent knows exactly when to stop.
By also keeping an eye on escalating actions and combining these safeguards, you can ensure the agent stays efficient and under control. This way, it avoids wasting resources or spiraling into unintended infinite loops.
"}},{"@type":"Question","name":"How do I estimate and reduce agent costs in production?","acceptedAnswer":{"@type":"Answer","text":"To keep agent costs under control, start by reducing token usage. You can do this by fine-tuning the context size and summarizing data effectively. Address the Unreliability Tax by identifying and fixing system errors or inefficiencies that may be driving up costs.
When it comes to API expenses, use techniques like batching, caching, and limiting unnecessary calls. If possible, consider deploying models locally to eliminate API-related costs altogether.
Finally, make it a habit to monitor token and compute usage regularly. This helps you fine-tune workflows and maintain efficiency without compromising on performance.
"}}]}

