Read less, build more: a 6-month roadmap teaching prompts, RAG, agents and production evals for new AI engineers.
If I were starting AI engineering in 2026, I would spend my first 6 months on three things: model basics, RAG, and production evals. I would skip deep training theory, read one book plus a few high-signal blogs and docs, and pair each reading block with a small build.
Here’s the short version:
- Start with ML basics like probability, metrics, embeddings, attention, and tokenization
- Focus on shipping, not training models from scratch
- Read papers like an engineer: abstract, conclusion, diagrams, methods, then implementation notes
- Study the stack that shows up in production: prompting, RAG, tool calling, MCP, evals, security, cost, and latency
- Use docs and blogs for day-to-day learning, not just books
- Ignore hype unless there are case studies, evals, and failure notes
- Build as you read: document QA, a niche RAG bot, or a small MCP server
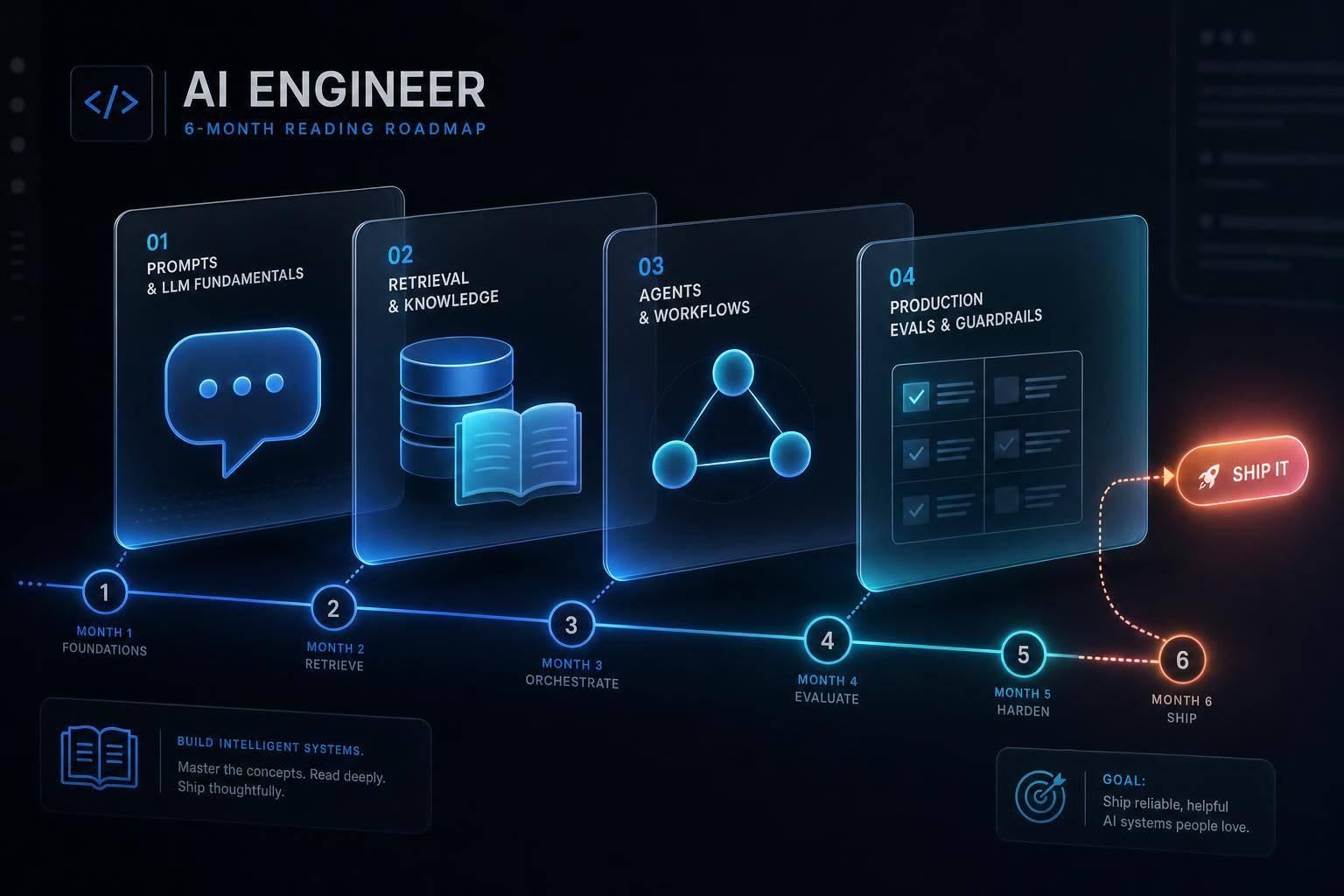
A simple path looks like this:
| Time | What I’d study | What I’d build |
|---|---|---|
| Months 1–2 | Prompts, tokens, context windows, streaming | Small chat app |
| Months 3–4 | RAG, chunking, vector DBs, hybrid search | Document QA assistant |
| Months 5–6 | Agents, tool calling, MCP, evals, prompt injection | Tool-using agent or MCP server |
The big idea is simple: AI engineering in 2026 is mostly system work. In many teams, the job is less about model training and more about choosing models, testing them, handling failures, and keeping quality, speed, and cost in check.
I’d use this guide the same way: read less, test more, and turn each source into one small shipped project.
Start Here: The Foundations You Actually Need
You don’t need advanced math. You do need enough theory to debug real problems and make sound architecture calls. AI engineering is the judgment layer of shipping AI systems: picking the setup, checking how well it works, and knowing where it breaks.
The best way to learn this stuff is alongside a small project. That gives the theory something to stick to. It also helps you debug your first systems with less guesswork.
Core ML Concepts That Still Matter in 2026
The ideas worth learning are the ones that keep showing up in production: probability, statistics, and evaluation metrics. A high score doesn’t mean much if the metric doesn’t match the job you’re trying to do.
You can skip heavy linear algebra. Instead, learn embeddings and optimization well enough to reason about retrieval and training. Embeddings are high-dimensional numerical representations where similar meanings sit near each other. That’s the basis of retrieval, which sits at the center of RAG. Optimization matters because it tells you what the model is trying to do during training.
Deep Learning and Transformers Without the Math Spiral
To debug LLM behavior, learn embeddings, attention, and feed-forward networks well enough to reason about outputs. You do not need to build them from scratch.
Tokenization matters a lot. It shapes cost, context limits, and failure modes. Add context windows and context rot to the mix, and you start to see what matters in practice. Focus more on latency, inference cost, and tool-calling behavior than on parameter count.
Once you can reason about the core parts, papers stop feeling like a math exam. They become a tool for judgment.
How to Read AI Papers as an Engineer
A lot of engineers do one of two things: they skip papers, or they get stuck in the math. There’s a better route.
Read papers in this order:
- abstract
- conclusion
- diagrams
- methods
- implementation notes
The abstract tells you the claim. The diagrams often hold the whole mental model. Methods show the mechanism. The conclusion tells you whether the idea held up. Implementation notes show what went wrong.
Start with the transformer paper and the original RAG paper. Then use newer papers to inspect tradeoffs, not to chase novelty. Filter every paper for limits and failure modes. Those details are what change how you build RAG pipelines, design tool calls, manage context, and evaluate reliability.
Next, turn this foundation into a short list of books, blogs, and docs worth reading end to end.
Books, Blogs, and Docs Worth Your Time
Best Books for AI Engineers Starting Now
Read for judgment, not coverage.
By 2026, AI engineering is mostly about building reliable systems around foundation models. That changes what’s worth your time. Start with books that help you see the whole stack clearly: how prompting works, where retrieval fits, and how to judge what you build. After that, move into books on system design, failure modes, and deployment trade-offs like latency, quality, and cost. Skip books that spend most of their pages on backpropagation math or GPU tuning unless you’re aiming for ML research.
The "Towards AI" e-book Building LLMs for Production runs 465 pages . It pairs well with something hands-on that covers RAG patterns, agents, and evals.
After books, turn to blogs. That’s where you see how these ideas play out in shipped systems, not just in neat diagrams.
Blogs That Teach Real AI Engineering
A small set of blogs can teach you a lot fast:
- Latent Space: architecture and infrastructure trade-offs
- Simon Willison's blog: real LLM experiments, security, and agent risk
- Lilian Weng's blog: agents, memory, tool use, and reasoning
- Hamel Husain: evals and prototype-to-production work
- Eugene Yan: patterns in shipped LLM products
Then move to docs. Blogs show what people learned. Docs show where systems break.
Docs to Read End to End, Not Just Search
Read docs end to end to surface constraints before production does.
Pick one LLM provider, one vector database, and one orchestration framework. Then read each set of docs fully. Start with the parts on rate limits, structured output errors, retries, guardrails, and observability. Those sections tend to save you from the pain later.
"The model is a commodity. The system around it - the prompts, tools, guardrails, memory, evaluation - is where engineering happens." - Mikul, Software Engineer
Read the Model Context Protocol (MCP) docs end to end. Do the same with the RAGAS and LangSmith docs so you understand what each eval metric is actually measuring.
Once the sources are clear, the next step is separating durable skills from short-lived hype.
What to Focus On Now vs. What Is Mostly Hype
Use the books and docs above as inputs. This section shows where your time should go first.
Skills to Prioritize in 2026
In 2026, the big question isn't whether you can train a model. It's whether you can make an existing model behave well in production.
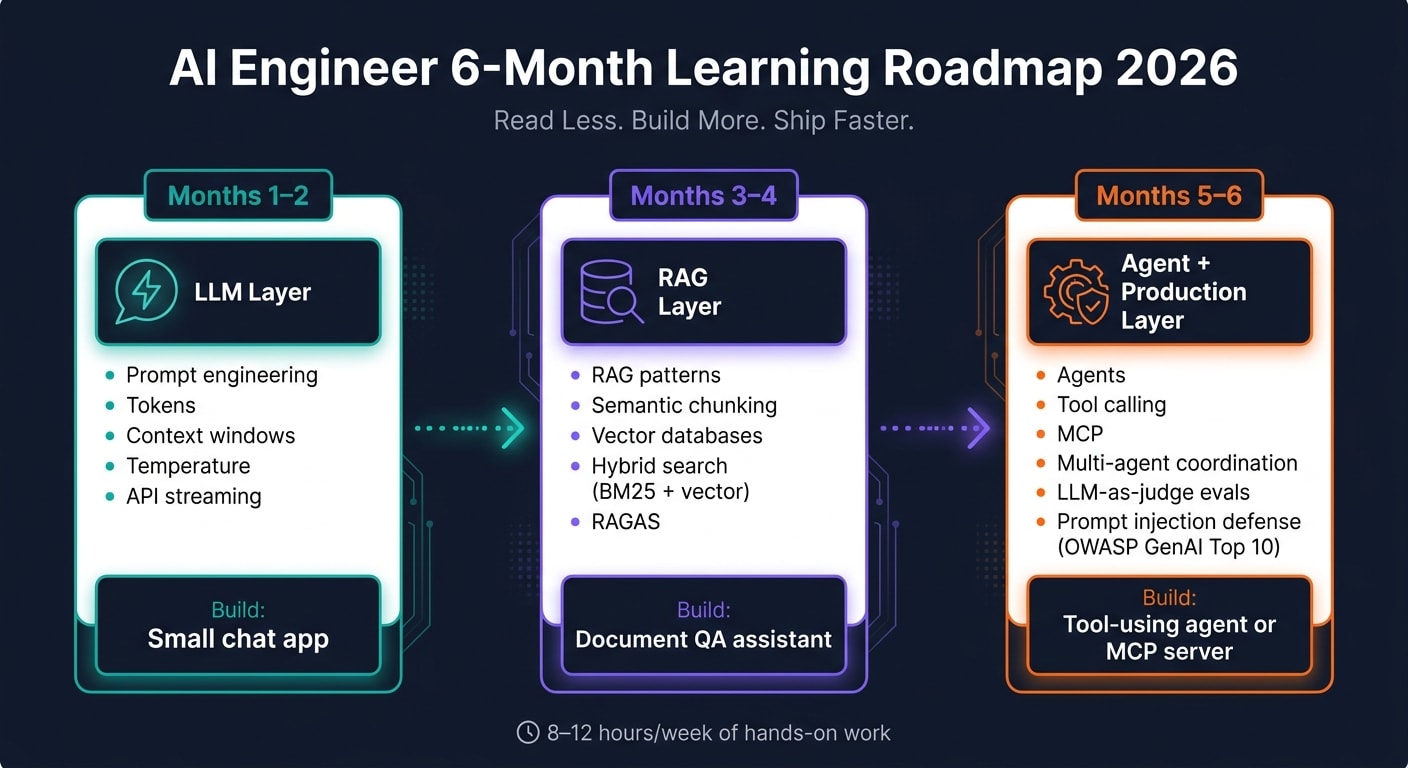
| Skill Layer | Specific Topics to Study |
|---|---|
| LLM Layer | Prompt engineering, context windows, temperature, structured outputs, local model trade-offs |
| RAG Layer | Semantic chunking, reranking, hybrid search (BM25 + vector), RAGAS |
| Agent Layer | Tool calling, MCP, multi-agent coordination, memory systems |
| Production | LLM-as-judge evals, prompt injection defense, cost and latency tracking |
That shift changes what companies test for. Technical screens now lean hard into debugging. If a RAG system keeps pulling irrelevant chunks, the issue is often retrieval or reranking, not the model itself.
How to Spot Hype Before It Wastes a Quarter
A simple red flag: big claims with zero discussion of failure. If a framework or pattern can't answer what happens when the model hallucinates? or what happens when the agent loops forever?, don't treat it as proven.
That also means being careful with "agents for everything" pitches and AGI talk. Those ideas may sound flashy, but they don't deserve your study time until they show repeatable production value.
Before you go deep on a new tool, ask:
- Is there a production case study?
- Are there measurable evals?
- Are the failure modes documented?
- Do the docs explain how to run it safely at scale?
If you can't get a clear yes to all four, put it on your watch list, not your learning queue.
Use those filters to decide what makes it into the next six months.
A First-Year Reading Roadmap
Once a topic clears the hype filter, tie it to a build and give it a set time box.
Use this six-month sequence with 8 to 12 hours a week of hands-on work. The order matters just as much as the topics.
- Months 1–2: Prompt engineering foundations, tokens, context windows, temperature, and API streaming.
- Months 3–4: RAG patterns, chunking strategies, vector databases, and hybrid search. Defer training models from scratch entirely.
- Months 5–6: Agents, tool calling, MCP, and evals (LLM-as-judge, RAGAS). Security basics - specifically the OWASP GenAI Top 10, starting with LLM01: Prompt Injection .
Pair each phase with one build. A niche RAG chatbot for your own notes works well. A small MCP server works too. The point is to watch theory collide with messy conditions.
"Most developers learn the happy path. Production AI work is 40% happy path, 60% understanding why it broke and fixing it." - Abraham Jeron, Engineer at Kalvium Labs
Stay Current with daily.dev and a Practical Plan
Use daily.dev as Your AI Engineering Feed
Once you know what to study, use daily.dev to keep the signal flowing without starting your research from scratch every week.
The reading list gives you depth. daily.dev helps you keep that depth current. Treat daily.dev like a filtered feed, not a firehose. Follow the topics you're actively building in - RAG, agents, evals, prompt and context engineering, local models, and MLOps. Then pin a few high-signal sources like Latent Space, Simon Willison's blog, and Lilian Weng so new posts stay easy to spot in your feed.
Use Search for narrow queries like "RAG chunking strategies", "prompt injection defense", "semantic caching," or "LLM-as-a-Judge" instead of browsing all over the place.
Use the same filter here too. Favor posts with:
- production examples
- measurable evals
- failure modes
- safe deployment details
The goal isn't to pile up more bookmarks. It's to support the project you're building right now. Stick to one topic cluster each week, save three strong posts, and turn one of them into a small build or eval.
Use the feed to pick one article to read and one idea to test each week.
Conclusion: Read Less, Read Better, Build More
The fastest path forward is to read less and start building sooner.
"The engineers who will thrive aren't the ones who learn the most tools. They're the ones who learn to build reliable systems with unreliable components." - Kunal Ganglani, Software Engineering Leader
Read less, read better, and turn each useful idea into a small build. Keep one curated feed, one reading habit, and one build in motion.
FAQs
Do I need math to start AI engineering?
No. AI engineering is mostly about building products and dependable systems with existing foundation models, not training new ones from scratch.
What matters most is strong software engineering skill: API integration, prompt design, RAG, orchestration, and evaluation. You should understand how embeddings, transformers, and vector databases work, but you do not need advanced math to ship production-grade AI applications.
Should I learn model training or focus on shipping first?
Focus on shipping first. In 2026, an AI engineer’s main job is to build reliable systems with existing foundation models, not train models from scratch.
That means the priority is practical work: integrating models, setting up RAG pipelines, building agentic workflows, and putting strong evaluation systems in place. Training still has a role, but it’s now a specialized tool for cases where you need better performance or lower cost, not the starting point for building AI products.
How do I know if an AI topic is hype?
A topic is probably hype when it leans on quick prompt tricks, demo-first chatbots, or automated coding “vibes” instead of the hard work required to build systems people can count on.
Real engineering looks different. It puts evaluation, monitoring, cost control, and failure handling at the center. That’s the unglamorous stuff, but it’s what keeps a system from falling apart the moment it leaves the demo.
When those basics are missing and the buzzwords start piling up, you’re likely looking at noise. It’s smarter to pay attention to patterns like RAG and agent loops that put reliability, testing, and system design first.