

Explore the technical journey of daily.dev in creating the "Weekly Digest" - a personalized weekly email feature. This detailed blog post covers challenges in sending over a million emails, user-specific content curation, scheduling complexities, and the use of technologies like GraphQL and Sendgrid. Perfect for developers and tech enthusiasts interested in email system implementation and personalized content delivery.
Recently in daily.dev we introduced a new feature called "Weekly Digest" 🗞️. This feature is a weekly email that includes the most relevant articles from the last week that users might have missed in their daily usage of our apps. The email is currently sent every Wednesday and it is a great way for our users to catch up with the latest news in the developer world. With all that good stuff of course comes a lot of complexity. In this "Under the Hood" blog post we will explore how we implemented this feature and what were the challenges we faced while trying to send more than a million emails a month.
Requirements
Before we start, let's define the requirements for this feature. These will be points that we will go through to explain our implementation process and something that you can potentially take back to your own project or use as a reference for similar feature implementation. Here are the requirements:
- The email should be sent every week but should be configurable to be sent on different day(s) and hour for each user
- The email should contain recommended articles since the last digest email the user was sent
- The email should be personalized for each user, meaning that each user should get different articles based on their interests
- The email template should be AB testable and adjusted based on the variation user belongs to
- The email should be sent in batches to avoid overloading the email provider
- The email should be sent in a way that will not affect the performance of the main application or other services
Saving and configuring user subscription
First things first, to save users' subscriptions we added a new table user_personalized_digest in our database. Table contains following columns:
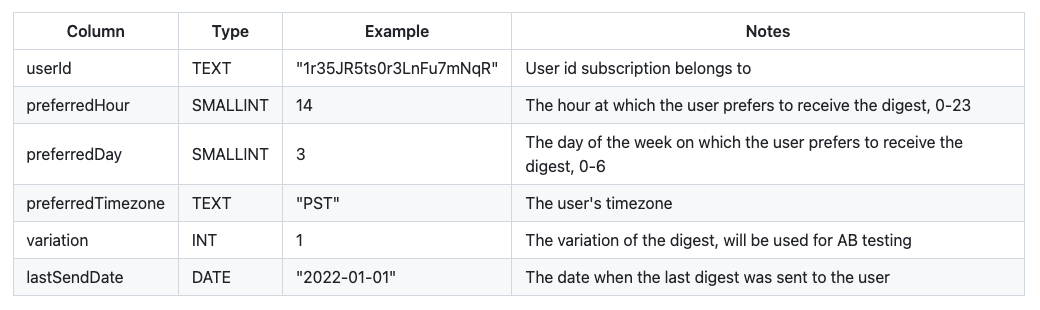
With the above table, we could easily create subscriptions for all of our users and also enable modifying those preferences on a per-user basis. Also, the variation column allows us to further modify the contents of the email based on the variation the user belongs to. This will be explained in more detail later in this post.
We also exposed new mutation in our GraphQL API that allows users to update their preferences but this of course can be implemented through REST API or in any way that suits your project.
Getting recommended articles
Since we already had an algorithm that we use to recommend articles each day for the user on "My feed" page at daily.dev and other parts of our apps we could reuse the same service with added date parameters to get articles since the last digest user read. Of course, you might not have such service so you could use custom logic to choose which articles or content goes into the digest email. The important part is to have an abstract interface that other content needs to match or normalization function that will adjust the content so it is suited for the email. In that way if service or the content changes you just have to adjust the single part of your codebase.
In our case, in addition to having a feed service, we also chose the latter so we implemented a helper that takes an array of recommended articles and transforms it into part of the data needed for our email template. The said function could look something like this:
const getPostsTemplateData = ({ posts }) => {
return posts.map((post) => {
return {
post_title: post.title,
post_image: post.image || pickImageUrl(post),
post_link: getDiscussionLink(post.id),
source_name: post.sourceName,
source_image: post.sourceImage,
};
});
};
Creating email template
We use Sendgrid as our email provider and we use their dynamic templates to create our email template. This allows us to create a template that can be easily modified and tested without having to redeploy our application. Templates are created on Sendgrid side (with HTML & CSS) and all we need to include in our code is a proper template ID and know which params are required. Then we normalize our data to match it with a function like getPostsTemplateData above.
For our digest, we have to create a unique email for each of our users. This differs from large batch and campaign emails we have been sending so far because it is not just personalization based on user data but it is content we have to generate for each user on demand at a specific point in time. This means that we need more processing power to generate each email and schedule send at the appropriate time per user's timezone. More on scheduling a bit later.
In the requirements above we also mentioned we need to be able to AB test the template and adjust it based on the variation some user belongs to. This is also possible with dynamic templates. We can assign users per variation column and then based on that value adjust the template data. Since this is our new feature we can not possibly know what the properties of the email we want to test will be. The approach we took here is that for each experiment we can implement specific logic into our template builder from above. This does require code changes for each experiment but it also does not limit what we can do.
For example, if we wanted to give users with variation: 2 different email title we could implement that logic directly in code inside the helper function getEmailVariation, the logic looks something like this:
// data is usual data we get from our template builder above
if (variation === 2) {
return {
dynamicTemplateData: {
...data,
title: `The posts you missed this week!`,
}
};
}
return {
dynamicTemplateData: data
}
While adding an experiment requires code changes disabling it does not. This is great because we can always update variation to the default value (eg. variation: 1) for any user(s) and that will disable the experiment if we need to revert 👍. We usually make those changes in bulk through custom scripts we can run on our database in a single transaction.
Sending emails
To send even a few personalized emails to users can be hard due to different parameters and variations so sending more than a million emails can be a real challenge.
Luckily Sendgrid has a cool feature called batch sending. This feature allows us to send multiple emails as a single batch that we can monitor, manage and cancel if needed. While this feature is great it does not solve all of our problems. We still need to generate each email and send it at the appropriate time per user's timezone and preferences.
Scheduling emails
Sendgrid also has a feature called scheduling parameters. This feature allows us to schedule emails to be sent at specific date & time in the future. Sendgrid allows us to schedule emails up to 72 hours in advance, which is plenty since we want our digest content to be fresh so we don't want to schedule or generate them too early
Both of the above features we enable by adding two parameters next to our dynamicTemplateData:
{
// created with above "batch sending" endpoint
batch_id: 'my-batch-id',
// UNIX timestamp for when the email should be sent
send_at: 1409348513,
}
Even though we use Sendgrid native features, many other email providers have similar features and you should be able to implement a similar solution with your email provider of choice. Sending a lot of emails involves a lot of complexity on other fronts and protocols such as SMTP, DKIM, DMARC, etc. so I would recommend moving that responsibility to an external service if possible. The crucial thing is to implement it in a way that is abstract enough so you can easily switch email providers if needed.
For example, some other abstractions in our implementation include:
- separate sendEmail function that is used to send emails and can be easily replaced with other implementation
- separate createEmailBatchId function
- separate getEmailSendDate function that calculates the send date based on user preferences and timezone
Mentioning getEmailSendDate function, let's talk about that one in some more detail. Because our users are from all over the world we need to send emails at appropriate time per their timezone. This means that we need to calculate the send date for each user based on their timezone and preferred time when they wish to receive the email. If you ever programmed any code that works with time zones you will know that it is never easy. For example, if user is in a timezone that is ahead of UTC (Coordinated Universal Time) and wants to receive the email at 9 AM we need to make sure the user receives it at 9 AM but in their timezone. This means that we need to calculate the send date based on user's timezone and UTC offset. We use the UTC because it is a great default. This also means that we need to schedule the email to be generated before any sending times in different time zones. The last issue is that we don't want to generate emails too early because then we might send the emails with outdated content, so we need to find the sweet spot where we generate and send the email at an appropriate time.
Since our application code runs in the UTC timezone we can take that as a constant and calculate everything else around it so we built our logic around that fact. These are the rules we set up:
- We run our digest generation code during the night approximately 24 hours before the midnight of the day when the email should be sent, this helps to avoid any timezone overlaps
- The code runs every day and pulls all users that should get the email on that day from the database
- For each user, we calculate the send date based on their timezone and preferences
- We schedule the email to be sent at the calculated send date with send_at parameter in Sendgrid
- We save the calculated send date in the database to mark the last time we sent the email to the user
Regarding the actual time calculation, we use date-fns as our date library but any package like dayjs or moment has similar functionality. Our function to calculate the sent date looks something like this:
import { nextDay } from 'date-fns';
import { zonedTimeToUtc } from 'date-fns-tz';
const getEmailSendDate = ({ personalizedDigest }) => {
const nextPreferredDay = nextDay(
new Date(),
personalizedDigest.preferredDay,
);
nextPreferredDay.setHours(personalizedDigest.preferredHour, 0, 0, 0);
const sendDateInPreferredTimezone = zonedTimeToUtc(
nextPreferredDay,
personalizedDigest.preferredTimezone,
);
return sendDateInPreferredTimezone;
};
The getEmailSendDate function gets the next day in a week based on user preference. So if today is Monday and user wants to receive the email on Wednesday it will return next Wednesday of the week. zonedTimeToUtc function converts the date to UTC based on user timezone. This is the date we will use to schedule the email to be sent (Sendgrid also works in UTC).
Generating each email
Now that we have scheduled the emails to be sent at the appropriate time we need to generate each email. Since we are processing hundreds of thousands of users and their preferences at the same time we want to implement that processing in a way that will not affect the performance of our main application or other services. Our system already uses workers to process other async tasks like sending notifications or processing articles so we can use the same pubsub (publish-subscribe) system to process our digest emails. There are many services for pub-sub like Google Pub/Sub, NATS or Kafka.
Since we have other async jobs and messages to process in our pub-sub system, to lower the impact and not delay their processing we also did the following:
- Use a separate topic just for generating and scheduling digest emails
- Use separate workers for digest emails (which was easy due to our archipelago architecture)
- Pull users data from the database as stream in batches to limit memory usage
Since our architecture allows us to create separate deployment units based on different labels and then scale them independently we can also easily scale our digest workers to process more emails when needed. The best thing is it will be done automatically by Kubernetes based on the load of the workers. So as our user base grows and we send more emails we don't have to constantly worry if our system can handle it. Even though scaling workers is great having big workers with loads of memory and CPU is not. This is why we split our generation process into two parts.
Cron job
Cron job in our system is just another worker task that executes at a specific time. This worker's job is to pull all users who should get the digest email on a specific day. For each user, the job pulls the preference (preferred day, timezone, variation) and publishes a message to generate-personalized-digest topic. This is done in batches of 1000 users to limit memory usage, sometimes ORMs (Object Relational Mapper) can be memory-hungry when creating entity objects for a large number of rows. Since publishing to the topic is an async operation we use fastq library to spread that load into batches and make sure all of the publishing operations are done before killing the cron worker. This worker also creates a single batch ID that is sent with user data to the topic. This is so we can group all the emails into a single batch on Sendgrid side. This then allows us to control, monitor and cancel the batch if needed.
Generate digest worker
As mentioned above this worker subscribes to the generate-personalized-digest topic and processes its messages. This worker is a separate deployment so our system can spawn as much of them as needed depending on the number of emails scheduled for generation, which can vary day by day. The worker accepts the message with user ID and preference data and then uses all the logic from previous sections to generate the email and schedule it to be sent at the appropriate time on Sendgrid side.
Since this worker talks to a lot of 3rd party and other internal services like recommendation service and Sendgrid we need to be ready for the case when any of those services fail for any reason, and yes, the reality is it can happen 😅. While our workers do have retry logic with back-off which incrementally retries processing with exponential delay due to large amount of messages we don't want to retry indefinitely. This is why we have implemented a dead letter queue (DLQ) for our workers. DLQ is a queue where all messages that fail to process after X number of tries are sent to die. The queue simply logs the failed message with its payload so we can easily debug any issues and schedule sending again if needed. While this solves the indefinite retry problem what can still happen is that some other error can occur while the email was already scheduled on Sendgrid side. Since we can not pull specific emails from Sendgrid batch we use lastSendDate column from our user_personalized_digest table to mark the last time the digest was processed. In case the worker tries to schedule an email for the user that was already scheduled we skip the processing. This ensures we always send a single email to each user per send date 🙌.
Connecting it all
We covered a lot of things so here is a diagram of how our processing works and how all of the services mentioned above interact and come together.
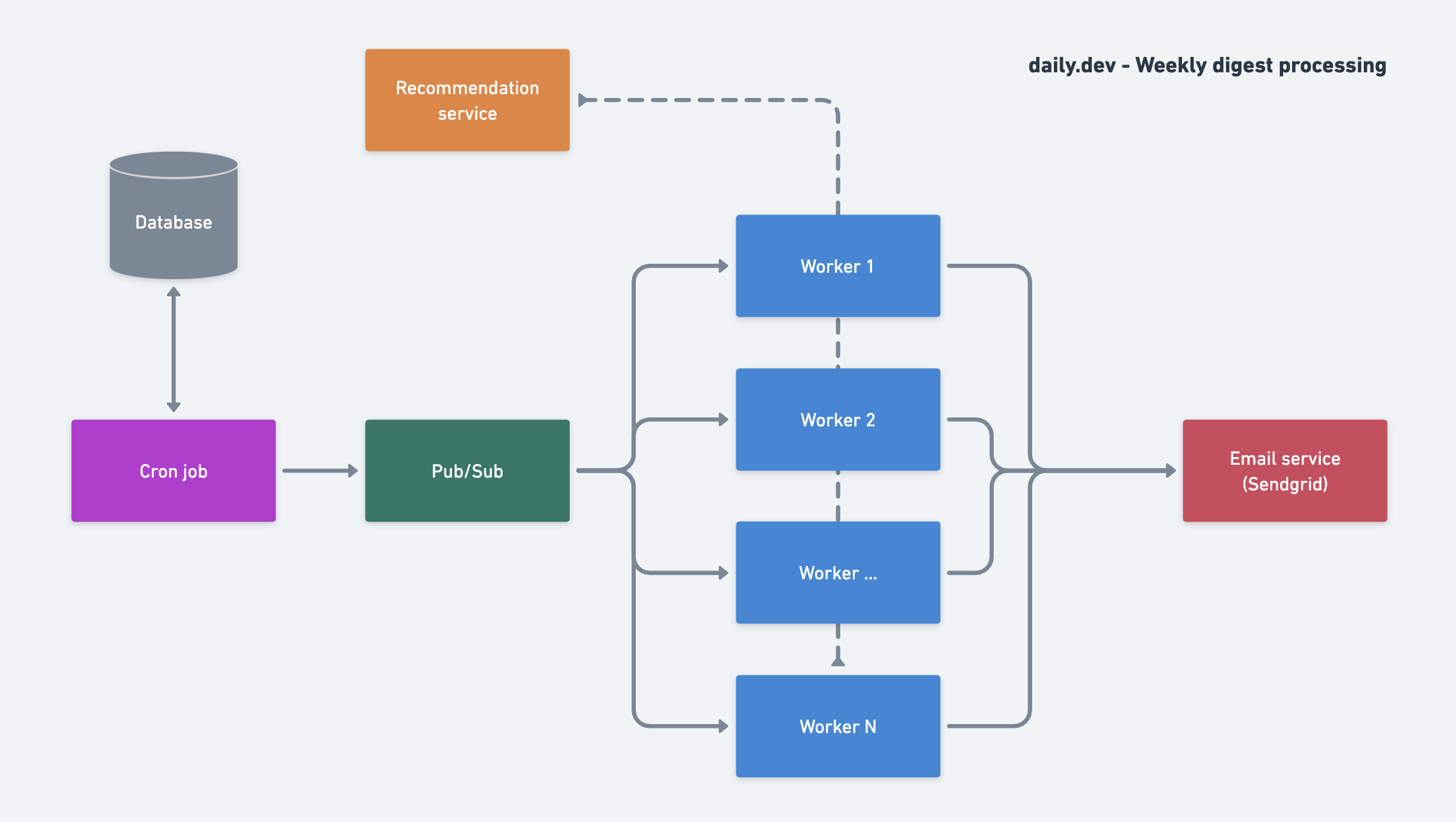
Conclusion
Currently, we are sending the digest email once a week but we are planning to add more options and are also constantly working on improving our recommendation algorithm. You can read more about "Weekly Digest" release in our announcement post 🚀. The best thing is that we already have a lot of groundwork and infrastructure in place so we can support expanding this feature 🤞. We are also constantly working and experimenting with our digest email to see what works best and to bring more value.
We hope you enjoyed this kind of more hands-on blog post 🛠️ and that you can potentially take some of our gotchas and ideas back to your own project(s). In addition to all the explanations and pseudo-code, you might be happy to hear that our API project (which is in charge of sending all of the emails) is open source so you can check out the real thing here. Enjoy! 🎉