Senior engineers stay current by trading volume for intention: curated feeds, 2–3 deep focus areas, production-based learning.
Staying current in 2026 is not about reading more. It’s about making better calls with less noise.
If I strip the article down to its core, the system is simple:
- I keep one tight reading funnel
- I go deep on 2–3 areas tied to my job
- I learn from incidents, postmortems, code, and diffs
- I use a small peer group to test ideas and cut hype
- I follow a fixed cadence so learning doesn’t get pushed aside
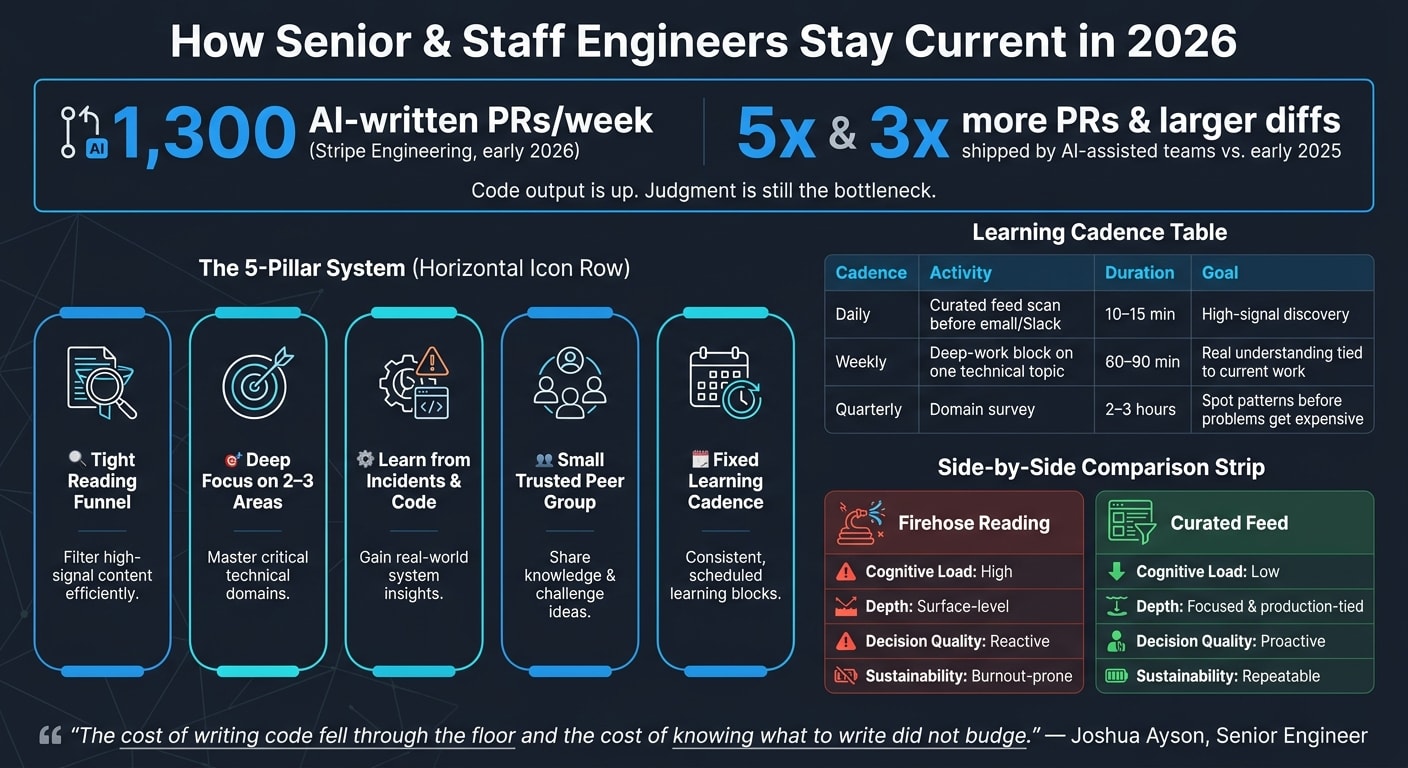
That matters more now because AI has changed the cost curve. The article notes that Stripe Engineering reported about 1,300 AI-written pull requests per week in early 2026. It also says AI-assisted teams now ship 5x more pull requests and 3x larger diffs than in early 2025. So code output is up. But judgment is still the bottleneck.
The big idea: I don’t stay current by chasing every new tool. I stay current by keeping my mental model of the systems I own close to how they behave in production.
What this looks like in practice:
- Daily: 10–30 minutes with a curated feed before email or Slack
- Weekly: 30–90 minutes to review saved reads or study one topic
- Quarterly: 2–3 hours to survey one domain tied to current pressure
Quick comparison
| Area | What I do | What I avoid | Why it works |
|---|---|---|---|
| Information intake | Use a curated feed and cut weak sources | Firehose reading | Less context switching, better focus |
| Learning scope | Study 2–3 job-linked themes | Tracking everything | Better pattern memory |
| Skill building | Learn from incidents and code | Leaning on tutorials alone | Closer to how systems fail |
| Peer input | Ask a few trusted engineers | Following hype waves | Better checks on bad assumptions |
| Routine | Protect time blocks on the calendar | “I’ll learn when I have time” | Makes the habit stick |
Bottom line: senior and staff engineers do not win by consuming more content. They win by turning a small set of inputs into sharper decisions, better code reviews, and fewer bad bets.
Build a small, high-signal information diet
For senior and staff engineers, staying current isn't about hoarding links. It's about filtering for judgment. The engineers who stay sharp tend to cut hard and guard their attention like it's in short supply. It starts with what you allow into your system.
Use daily.dev as your main discovery funnel
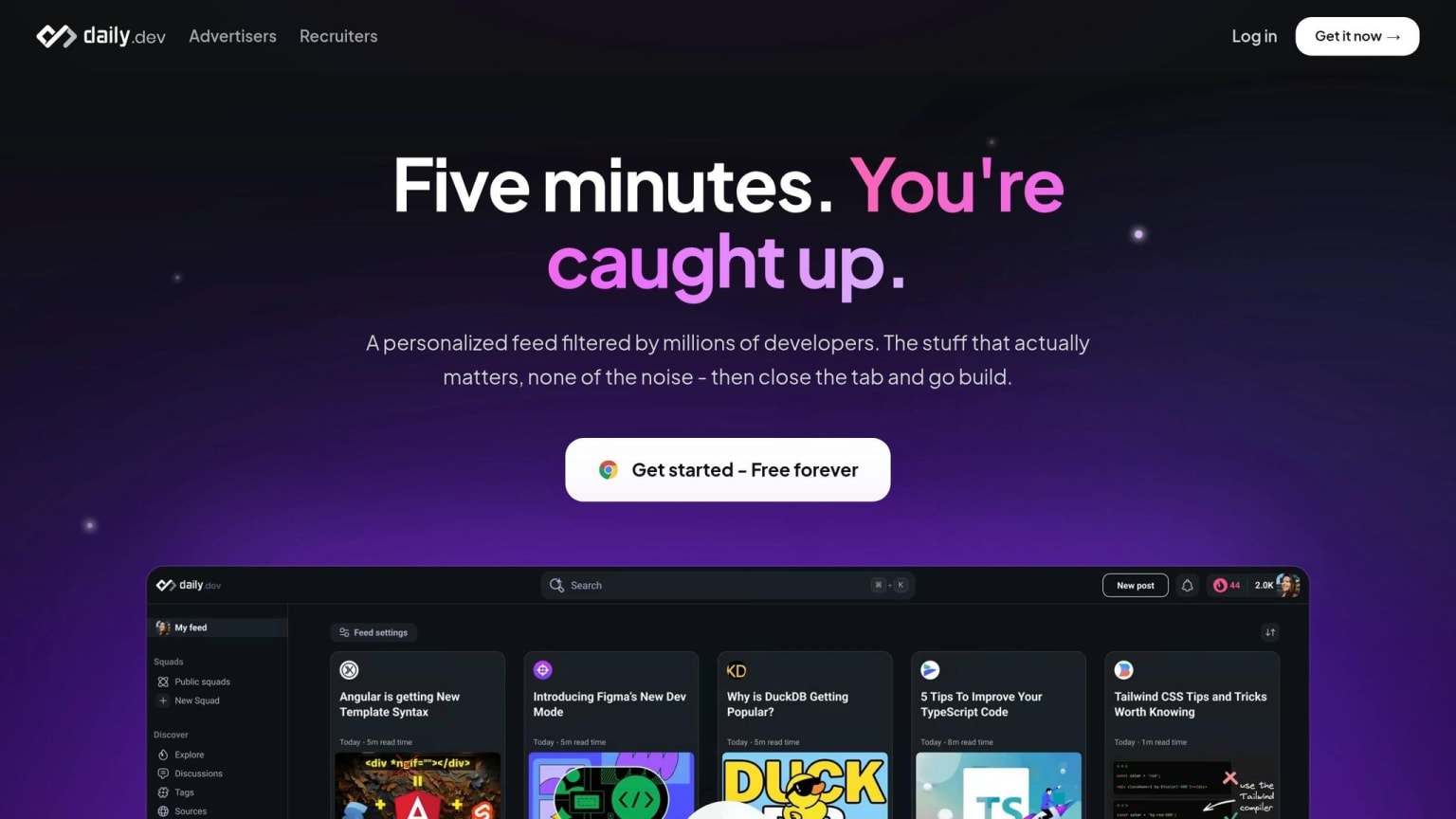
Use one personalized feed tuned to the systems you own. daily.dev pulls together engineering blogs, release notes, and community posts into a feed shaped around your stack and interests - React, Kubernetes, PostgreSQL, observability, or whatever you work on day to day.
Put that feed in your new tab so you see it before email takes over. That order matters. Your inbox pushes you into reactive mode. A curated feed helps you stay selective.
Use Search when you need answers during a sprint or incident. Use Squads to follow focused communities around your stack or domain. You can also save posts and come back to them during a set reading block.
Use daily.dev to keep your mental model up to date on the systems you own.
Pair daily.dev with a short reading routine and decision notes
Stick to a fixed routine: 15–30 minutes each weekday to scan your feed, plus one 30-minute block each week to process saved posts.
"The discipline is what matters, not the duration."
- Nimrod Kramer, CEO, daily.dev
Write down only three things: what you learned, why it matters to your systems, and when you'll use it . If a source goes a full month without giving you actionable insight or a pattern you can reuse, cut it .
Once your feed is tight, spend more time on the few themes that matter most.
Firehose reading vs. curated inputs: a side-by-side look
That difference matters because the goal is better judgment, not more reading.
| Firehose | Curated Feed | |
|---|---|---|
| Cognitive load | High - constant context switching | Low - time-boxed reading |
| Depth of understanding | Surface-level; fragmented learning | Focused; tied to real work |
| Decision quality | Reactive; trend-driven | Proactive; grounded in production patterns |
| Long-term sustainability | Burnout-prone | Repeatable and sustainable |
Go deep on a few themes instead of tracking everything
Once your feed is tight, put that attention into a small set of themes. That’s where reading starts to shape better technical judgment. The goal isn’t depth for its own sake. It’s depth in the systems you own.
Pick 2–3 focus areas that match your actual responsibilities
The best focus areas map to the constraints sitting in front of you right now. If latency is hurting your service, study the mechanics behind it, like batching and caching. If LLM inference costs keep climbing, spend time on semantic caching and model routing. Let today’s pressure tell you what to study next.
A good rhythm is to spend 2–3 hours once a quarter surveying one domain. The point is to spot common solutions before you need them, so when a pattern shows up in an incident or roadmap call, you’ve seen it before. Keep the list short. Two or three focus areas build on each other. Five or six pull your attention in too many directions.
Depth helps you notice repeat failure patterns before they settle in.
Deep-dive methods that build reusable judgment
Once you’ve picked a theme, shift from casual reading to system-level examples. Use daily.dev to gather a short reading series on that topic - a few posts from engineering blogs at companies like Netflix, Cloudflare, or Stripe that show what production systems look like under load and under stress. Then go one layer deeper: read source code, diffs, and release workflows from mature open-source projects in the same area. That’s where you start building a mental model for how systems fail, recover, and scale.
Pull out principles you can carry from one stack to another:
- idempotency
- backpressure
- fault isolation
- batching
Those patterns still matter even when the hot framework changes next quarter.
Breadth-only learning vs. depth-first learning: a side-by-side look
You can see the gap most clearly in design reviews, on-call work, and roadmap calls.
| Breadth-Only Learning | Depth-First Learning | |
|---|---|---|
| Architecture impact | High risk of hype-driven decisions based on fragments | Decisions grounded in system mechanisms and real trade-offs |
| On-call effectiveness | Surface-level troubleshooting | Deep debugging across service boundaries |
| Career leverage | Value tied to implementation speed | Value tied to judgment: knowing what should be built and why |
In early 2026, Stripe Engineering reported AI agents writing approximately 1,300 pull requests weekly . Reviews and architecture calls still depend on human judgment.
"The cost of writing code fell through the floor and the cost of knowing what to write did not budge." - Joshua Ayson, Senior Engineer
Learn from production systems, incidents, and real code
Depth shows up when you test what you know against live systems. Books and tutorials give you the language. Production gives you judgment. And that gap matters even more now, because production work - debugging fuzzy symptoms and owning reliability - still leans on human judgment .
Treat incidents and postmortems as core learning inputs
Every incident is a compressed case study. When something breaks, grab the logs, traces, metrics, and a timeline before memory gets fuzzy. Then look past the surface symptom and find the repeat pattern underneath it - retry storms, cache stampedes, pool exhaustion, cascade failures. These patterns come back again and again.
You also need a baseline for normal behavior. One habit that pays off: review dashboards when nothing is broken. Spend 20 minutes every Monday morning looking at the last 7 days of latency distributions, connection pools, and error rates. That gives you a baseline, which makes it much easier to spot drift before alerts go off.
Keep a private incident log, too. Write down what broke, which architectural decision made that failure possible, and how you'd catch it sooner next time. After a while, that log turns into a pattern library. Public postmortems from Cloudflare, AWS, and GitHub can do the same job. Read them like case studies that compress years of on-call experience into a weekly habit.
Read important code and diffs on purpose
Set aside time to read code that isn't yours. Pick a core service your team depends on and trace its critical paths so you can map data flow and spot likely failure points. Then look at the dashboards next to that code. That's where things start to click: you connect code paths to runtime behavior.
After that, study the changes that reshape those paths. A big diff in a shared service deserves careful attention. In 2026, AI-assisted teams ship 5x more pull requests and 3x larger diffs than in early 2025 . More volume means more things slip through. The people who catch them are usually the ones who read diffs on purpose, not just when they happen to cross their screen. Pay close attention to the seams:
- Service boundaries
- External calls
- Assumptions that only hold at small scale
Tutorials only vs. production-based learning: a side-by-side look
| Tutorial-Based Learning | Production-Based Learning | |
|---|---|---|
| Realism | Clean, abstracted, and optimized for completeness | Messy, ambiguous, and multi-causal |
| Relevance | Often covers tools you don't yet need | Directly tied to expensive pain and real-world constraints |
| Depth | Builds vocabulary and theoretical concepts | Builds judgment and pattern recognition |
| Outcome | Feels smart, improves little | Ability to predict failure modes before they happen |
Use a trusted network and a routine you can keep
Build a small network that filters hype and shares field-tested patterns
Once you can read incidents and code, the next filter is people who’ve already shipped similar systems. Articles and postmortems help, but peers add the part you can’t get from a write-up: what held up in production and what fell apart.
Inside your company, that usually means showing up to architecture reviews, tech lead syncs, and incident review circles with specific questions. Bring artifacts with you so people can push on your assumptions instead of speaking in generalities. You can also use daily.dev Squads to stay focused on one topic with engineers who’ve already put those ideas to work.
Most of your time should go to contributing. Use the rest to absorb patterns you can reuse later.
When it comes to hype, many experienced engineers keep it simple with a 2-year filter: wait until a new technology has survived at least two years in production before you spend serious time on it.
Run a weekly and quarterly cadence you can stick to
Meetings, incidents, and roadmap work will eat every open slot if you let them. A trusted network only helps if you’ve made space for it on your calendar first.
A fixed cadence helps learning survive busy weeks:
| Cadence | Activity | Duration | Goal |
|---|---|---|---|
| Daily | Curated feed skim (daily.dev) before opening email or Slack | 10–15 min | High-signal discovery before reactive work |
| Weekly | Deep-work block on one technical topic | 60–90 min | Build real understanding on something tied to current project goals |
| Quarterly | Domain review | 2–3 hours | Survey one area, like observability or API contracts, before problems get expensive |
"Learning is not a content problem; it's a consistency problem." - Praveen Suthar, Engineering Lead
The daily habit is the anchor. If you open daily.dev before Slack or email, your first 15 minutes go to something you picked, not whatever hit your inbox first. That small shift matters more than it sounds.
The weekly block is where you go deep on one topic tied to current work. The quarterly block is where you zoom out, review one domain, and look for better patterns before you’re forced to fix the same problem under pressure.
Two guardrails help keep this from slipping:
- Protect the deep-work block like a meeting you won’t move.
- Keep your input channels curated so they don’t slide back into noise.
Conclusion: The system senior and staff engineers actually use
Keep the rhythm small and repeatable. The pattern across this guide is simple: trade volume for intention. Senior and staff engineers who stay current aren’t reading more. They’re reading better, learning from the systems they already own, and leaning on a small peer network that tells them what’s real.
The system itself is straightforward: curated discovery, a few deep focus areas, production-based learning, and a small peer network on a fixed cadence. It doesn’t need extra hours. It needs a few recurring time blocks that stay protected.
FAQs
How do I choose my 2–3 focus areas?
Start with the biggest challenges in your current project or architecture. Pick 2–3 topics tied straight to what you’re building so what you learn pays off right away.
Then use a 2-year filter. Skip the hype. Put your time into areas that are still likely to matter in two years, show up in senior-level job descriptions, and help you bring something extra in places like database performance, production debugging, or security.
What should I save in a private incident log?
Write down what each incident taught you so you can build a personal runbook you’ll actually use. Put extra attention on the production issues you solved yourself, especially the messy ones that hit late at night or came with little to no documentation.
What matters most is the how. Note what broke, how the failure showed up, which signals pointed you in the right direction, and what steps led to the fix. Over time, that gives you a practical reference you can lean on when the next incident shows up looking weirdly familiar.
How do I keep a learning routine during busy weeks?
Focus on consistency over intensity. Protect a short daily window - usually 15 to 30 minutes - before you check email. When you turn it into a ritual, it gets much easier to stick with. For example, opening daily.dev at 8:00 a.m. to scan curated headlines cuts down on decision fatigue and helps you avoid starting the day with other people’s priorities.
On busier days, save articles for lunch or short breaks. A high-signal information diet means even limited learning time can still add up.