
Explore the core components and advanced concepts of GraphQL architecture, including schemas, resolvers, data sources, federation, pagination, and security considerations. Learn how to set up a GraphQL environment, overcome common challenges, and leverage GraphQL's full potential in your projects.
GraphQL is a powerful tool introduced by Facebook in 2012, designed to make data retrieval efficient and flexible. Unlike traditional REST APIs, GraphQL allows clients to request exactly what they need, making it a popular choice among developers for its efficiency and flexibility. Here's a quick rundown of what you'll discover about GraphQL architecture:
- Flexible data retrieval: Request exactly what you need in a single query.
- Efficiency: Reduces over-fetching and under-fetching of data, optimizing performance.
- Strongly typed schema: Ensures reliable data exchange.
- Real-time data with Subscriptions: Stay updated with the latest changes.
- Error handling: Built-in mechanisms to handle and report errors effectively.
This guide will explore the core components of GraphQL architecture, including schemas, resolvers, and data sources, and how GraphQL compares to REST APIs. We'll also delve into advanced concepts like federation, pagination, and security considerations, providing practical insights into setting up a GraphQL environment and overcoming common challenges. Whether you're new to GraphQL or looking to deepen your understanding, this introduction will equip you with the knowledge to leverage GraphQL's full potential in your projects.
What is GraphQL?
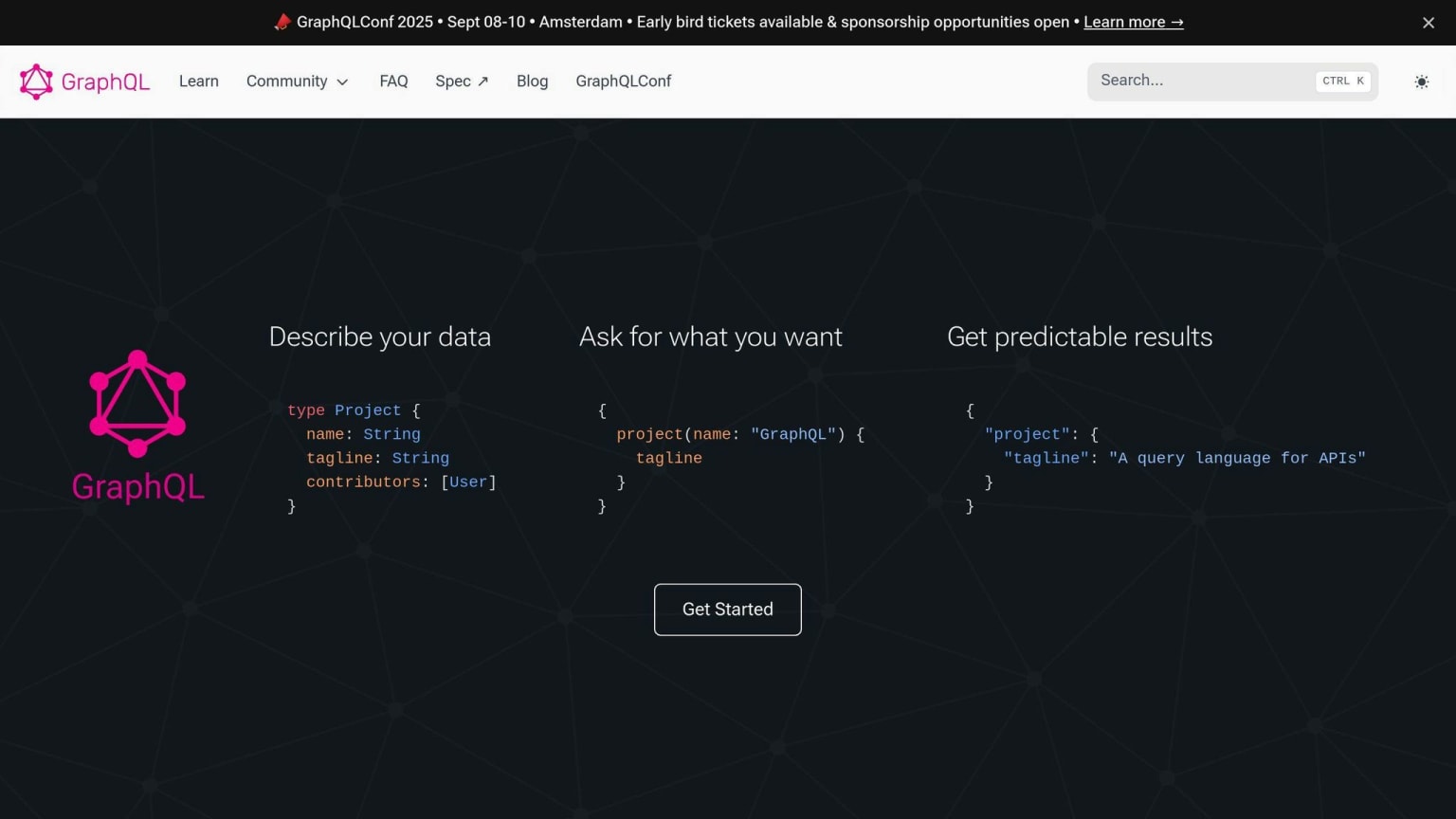
With GraphQL, you can tell a website exactly what info you want, and it gives you just that. This is different from older ways of getting data, where you might have to ask several times to get what you need.
Key things about GraphQL include:
- Query language - It has its own way of asking for data that's easy to understand.
- Strongly typed - It uses a strict system for organizing data, which helps catch mistakes early.
- Hierarchical - You can ask for a bunch of related info in one go. For example, getting a blog post and all its comments together.
- Runtime - There's a special engine that figures out how to get the data you asked for.
- Flexible - You can get exactly what you need, which means no wasted effort.
A Brief History of GraphQL
Facebook made GraphQL in 2012 because they needed a better way to get data for their apps. They shared it with everyone in 2015, and now lots of companies use it.
How GraphQL Works
Basically, you send a request to a single place, and GraphQL takes care of figuring out how to get what you asked for. It uses:
Schema - A plan that shows what data is available and how it's connected.
Queries - How you ask for data. You write what you need, and GraphQL gets it for you.
Resolvers - These are bits of code that find the data you asked for from databases or other places.
Mutations - If you need to change data, you use mutations.
Subscriptions - This lets you get updates in real time, like notifications.
GraphQL vs. REST APIs
GraphQL and REST are two ways to get data from the web, but they do it differently. With GraphQL, you use one place to ask for what you need, and it's very flexible. REST has many places to ask for data, and what you get is more fixed. Both have their pros and cons, but GraphQL can be really handy for getting data in a more tailored way.
Core Components of GraphQL Architecture
GraphQL's setup is made of three main parts that help apps get and use data efficiently: the schema, resolvers, and data sources.
The GraphQL Schema
Think of the schema as a map for a GraphQL API. It shows the kinds of data and how they're linked, so apps know what they can ask for. Schemas use a special language to outline:
- Types - These are like data shapes, telling you what kind of information you can work with. They include simple types like text or numbers, and more complex ones for bigger pieces of data.
- Queries - These are requests to read or get data.
- Mutations - When you want to change data, you use these.
- Subscriptions - These let apps get updates in real time.
Schemas make it clear what data is available and how to ask for it.
Resolver Functions
Resolvers are like helpers that fetch the data for what you've asked in the schema. For each piece of data you want, there's a resolver that goes and gets it.
They do things like:
- Talk to databases, services, REST APIs, and other places where data lives
- Check if you're allowed to see the data
- Make sure data looks right
- Combine data from different places
Resolvers make sure that the schema's promises about data are kept by actually fetching and preparing that data.
Data Sources
GraphQL can work with all sorts of data places, like:
- SQL databases - Think of popular ones like PostgreSQL or MySQL
- NoSQL databases - These are more flexible databases like MongoDB
- REST APIs - Services on the web
- File systems - Where files are stored
By using GraphQL, apps don't have to worry about where the data comes from. It acts as a middle-man, making it simpler for apps to get only what they need.
In short, the schema, resolvers, and data sources are the backbone of GraphQL. They help keep things organized, fast, and scalable when dealing with data.
GraphQL Server Architectures
GraphQL can be set up in a few different ways, depending on what you need it for. Here are some common setups:
Standalone GraphQL Server
Think of this as a one-stop shop. A standalone GraphQL server handles everything related to the database itself. This setup is great for new projects that don’t need to connect to existing data systems.
What you need to know:
- The GraphQL setup closely follows the database structure
- Special functions, called resolver functions, manage reading and writing data
- It’s a straightforward setup with just one GraphQL endpoint to manage
Imagine we’re making a blog. We’d define a Post type in GraphQL and connect it to a PostgreSQL database to store our blog posts.
Integrating Existing Backend Systems
GraphQL can also act as a middle layer on top of your current systems, giving you a unified way to talk to them. This is handy for adding new features without messing with your old systems.
What you need to know:
- GraphQL routes requests to the right backends, like databases, microservices, or REST APIs
- It simplifies things by hiding the complexity of your systems behind a clean GraphQL interface
For example, an online store could use GraphQL to pull together product information from an old database and order details from a third-party service.
Hybrid Approach
A mix of the first two, this approach directly handles some data while also connecting to external services for other needs.
What you need to know:
- The GraphQL server talks directly to a database for some data
- It also uses resolver functions to hook into external services for other information
- This gives you the best of both worlds: control over your data and the ability to connect to other services
With our blog example, we could keep posts and basic user info in PostgreSQL and use GraphQL to add comments from an external service like Disqus.
Each of these setups shows how flexible GraphQL can be, fitting different needs whether you’re starting fresh or building on top of existing systems.
Advanced GraphQL Concepts
Federation and Microservices
In GraphQL, federation means you can break up your big GraphQL API into smaller parts, called subgraphs. Each part has its own set of rules, helper functions, and data sources. A special tool called a gateway puts these parts together and shows them as one big API to users.
Why do this? Well, it lets:
- Teams work separately - Different groups can focus on their part without stepping on each other's toes.
- APIs stay neat - Instead of one huge list of commands, you get smaller, specific ones.
- Easy updates - You can switch to this setup bit by bit, which is less overwhelming.
Here's how it works with Apollo Federation:
- Each part tells the gateway what it can do.
- The gateway checks if everything fits together.
- If it does, it mixes them into one API.
For users, it feels like there's just one service. The gateway takes care of sending requests and combining answers from different parts quietly.
Pagination, Filtering and Sorting
When dealing with a lot of data, we need smart ways to handle it without overloading the server. We use:
- Cursors - Think of these like bookmarks that help you remember where you are.
- Limit and offset - These help control how much data you get and where to start.
- Search parameters - These let you narrow down what you're looking for.
- Sorting - This arranges your data in a certain order.
We also make things faster by using shortcuts, storing data for quick access, and handling many requests at once.
Here's a simple way to set up pagination:
type Query {
products(first: Int, after: String): ProductConnection
}
type ProductConnection {
edges: [ProductEdge]
pageInfo: PageInfo!
}
type PageInfo {
endCursor: String
hasNextPage: Boolean!
}
Security Considerations
With GraphQL, we must keep data safe by:
- Authentication - Making sure only the right people can see data. This often uses special keys or codes.
- Authorization - Making sure people have permission to see or do things.
- Threat protection - Keeping the bad guys out with things like rate limits and filters.
- TLS - This is like putting a letter in an envelope. It keeps messages between users and the server private.
Apollo Studio helps with security by:
- Checking that the setup is correct.
- Watching out for harmful requests.
- Offering tools for more security steps.
Other tips include:
- Don't let queries get too complicated.
- Always clean and check the data coming in.
- Use pagination and limits to keep things running smoothly.
GraphQL in Practice
Setting up a GraphQL Environment
To start using GraphQL, here's a simple guide to get everything ready:
- Install Node.js and npm - First, download and install Node.js and npm. These tools let you run JavaScript and add GraphQL packages to your project.
- Set up an Apollo Server - Apollo Server is a well-known tool for working with GraphQL. Type
npm install apollo-server graphqlin your terminal to add it. - Install GraphiQL - GraphiQL is a tool that makes it easy to try out your queries and see how they work. You can add it by typing
npm install graphql-playground-react. - Add Editor Plugins - Adding the Apollo GraphQL plugin to VS Code, or a similar tool for your code editor, will help a lot. It makes coding easier with features like highlighting and autocomplete.
After these steps, you'll have a setup that lets you build and test your GraphQL APIs easily!
Building a Simple GraphQL API
Let's make a basic GraphQL API with some simple data:
- Define types - Start by using the GraphQL language to describe
BookandAuthortypes with fields likeid,name,genre, etc. - Set up query and mutation types - Create basic types for fetching (
Query) and changing (Mutation) data. - Create resolver maps - Connect your types to functions that bring back real data. For now, we can just use some made-up book and author data.
- Start Apollo Server - Get your Apollo Server running so your API is up and ready at a specific web address.
- Test with GraphiQL - Use GraphiQL to try out different queries and mutations to make sure everything is working right.
This example might be simple, but it shows the key parts of a GraphQL API, like the schema, resolver functions, mutations, and how to test them.
Real-world Use Cases
Big companies use GraphQL for their websites and apps:
- Facebook - The creators of GraphQL use it to make their news feed work better.
- Twitter - Switched to GraphQL for updating timelines and showing tweets as they happen.
- Shopify - Uses GraphQL for its shopping platform.
- Airbnb - Uses GraphQL for both its mobile and web apps, and internal tools.
The main perks are better performance for mobile apps, quicker development of new features, and easier to manage code. Common uses include:
- Content APIs - Makes it simpler to publish content on different platforms.
- Real-time data - Great for updates that need to happen right away, like live scores.
- Native mobile apps - Helps reduce the amount of data sent to mobile devices, making apps run smoother.
As GraphQL becomes more popular, it's turning into the go-to way for companies to build fast, efficient APIs.
Overcoming Challenges
Common Challenges and Solutions
Using GraphQL can make things faster and easier, but it can also bring up some tricky problems. Here are a few common ones and how to fix them:
N+1 Requests
Sometimes, GraphQL can make too many small requests to get related data, which slows things down. Here's how to fix it:
- Batching - Group several requests into one to cut down on back-and-forth. Tools like Apollo Client do this for you.
- Data loader - This helps by storing and grouping data requests.
- Persisted queries - This means saving frequently used queries on the server to speed things up.
Caching
Storing data smartly can make responses quicker. Here's how:
- CDN caching - Save query results in a cache to avoid redoing them. Make sure to use proper cache settings.
- Automatic persistence - Tools like Apollo Client can automatically save query results for later.
- Dataloader - Again, this tool is great for managing data requests efficiently.
Schema Complexity
As your schema grows, it can get too complicated. To keep it manageable:
- Modularization - Split your schema into smaller parts. Use Apollo Federation to stitch them together.
- Deprecation - Remove old parts of your schema gradually.
- Limits - Set rules on how complex or deep queries can be to prevent overloading.
Best Practices
Here are some tips to make working with GraphQL smoother:
Schema Design Tips
- Design your schema based on what the user interface needs, not how your database looks.
- Start with a simple schema and add to it as needed.
- Use common fields between types to keep things organized.
- Plan to remove old fields slowly over time.
Data Loading
- Use data loaders to handle data from related sources all at once.
- Separate actions that change data (mutations) from those that get data (queries).
- Be smart about caching and setting cache rules.
Tooling
- Use tools that generate code for you.
- Monitor your system with tools like Apollo Studio to see how it's doing.
- Set up your system to save frequently used queries.
Error Handling
- Use the right error codes as recommended.
- Make sure error messages are clear for the people using your system.
- Use special exceptions to point out specific problems.
By watching out for these issues and following these tips, you can avoid a lot of the common problems that come with using GraphQL.
The Future of GraphQL
GraphQL is still pretty new, but it's already being used by big companies like Facebook, GitHub, and Shopify. As it keeps growing, let's talk about what might happen next with GraphQL:
Wider Adoption of GraphQL in Production
Right now, lots of companies are just trying out GraphQL to see how it works. But as we figure out the best ways to use it and get better tools, more and more teams will start using GraphQL for real projects. Cloud services like AWS AppSync are making it easier for teams to use GraphQL too.
Increased Use of CDNs
CDNs (Content Delivery Networks) make websites and apps faster by storing content in different places around the world. As more people use GraphQL, we'll likely see more use of CDNs to help GraphQL APIs handle more users from all over. Tools like Apollo Server can already use CDNs to make GraphQL faster.
More Code Generation and Productivity Tools
Making things easier for developers is super important. We'll see more tools that help build GraphQL APIs quicker, like tools that automatically create resolver functions and database code. For those making apps, tools that generate code for things like TypeScript and React will help cut down on extra work. Tools like GraphQL Playground make it easier for developers to test and work with their GraphQL APIs.
Growth of Database-as-a-Service Solutions
As more people start using GraphQL, we'll see more databases designed to work well with it. These databases on the cloud, like FaunaDB and Dgraph, help teams focus on building their apps and APIs without worrying about the backend stuff.
Increased Modularization
As GraphQL APIs get bigger, finding ways to organize them better will be key. Apollo Federation lets you split your API into smaller parts that work independently but look like one big API to users. This means teams can work on their own parts without messing with the whole thing.
In short, GraphQL has a lot of room to grow. It's a flexible way for developers to get and use data, and it's becoming more popular because it makes building and using apps and websites better.
Conclusion
GraphQL is a smart way for people who make apps to get the data they need from servers. It's good because it lets you ask for exactly what you need, which means you don't get too much or too little information. This is really helpful, especially for mobile apps that need to be careful with how much data they use and how fast they run.
Here are the main good points about GraphQL:
- More efficient - You can get just the data you need, which helps avoid wasting time and resources. This is great for apps that need to work fast and not use too much data.
- Flexible - It doesn't matter what programming language you're using; GraphQL works with many. Plus, it can bring together data from different places smoothly.
- Easy for developers - It has built-in help like documentation that makes it easier for new developers to understand what data is available. Things like autocomplete make coding faster and less of a headache.
- No need for multiple versions - You can add new features without messing up what already works. This means you can improve things without having to start over.
- Good for big projects - If you're working on a large project, GraphQL lets you break it down into smaller parts. This makes managing everything a lot simpler.
As more people start using GraphQL, we're going to see even better tools and services that make it easier to use and more powerful. If you're looking for a way to handle data that's efficient, flexible, and strong, GraphQL is a really good choice.
Appendix A - GraphQL Resources
GraphQL is a powerful tool for building APIs, known for its flexibility and how it lets you ask for exactly what you need. If you're interested in learning how to use GraphQL, here are some resources that can help:
Tutorials
- Fullstack GraphQL Tutorial - A detailed guide to creating an app with React and GraphQL.
- Building a GraphQL Server - The official GraphQL site offers an interactive tutorial to help you build a GraphQL schema and figure out resolvers.
- Using GraphQL With Django - A step-by-step tutorial for integrating GraphQL into Django projects.
Tools
- GraphQL Playground - A popular tool for testing GraphQL queries and mutations.
- Apollo Client - A tool for connecting JavaScript apps to GraphQL.
- GraphiQL - A tool you can use in your browser to explore GraphQL APIs.
Libraries
- Graphene - A Python library that makes it easy to build GraphQL schemas and types.
- Apollo Server - A comprehensive JavaScript server for GraphQL.
- graphql-java - A GraphQL implementation for Java applications.
Specifications
- June 2018 Specification - The most current official GraphQL specification.
- GraphQL Draft Specification - The working draft for ongoing updates to the specification.
- RFC Spec Process - Explains the process for making changes to the GraphQL specification.
These resources offer a wide range of information for getting started with GraphQL, from tutorials and tools to libraries and official specifications.
Appendix B - Glossary of Terms
Here are simple explanations for some important terms we've talked about in this guide:
Schema - Think of this as a blueprint for a GraphQL API. It shows what kind of information is available and how everything is connected.
Query - This is how you ask for specific data from a GraphQL API. It's like making a specific list of what you want.
Mutation - When you want to add, change, or delete data, you use a mutation. It's a way to tell the API what changes you want to make.
Resolver - These are the workers that take care of your requests, whether you're asking for data (query) or changing something (mutation). They know where to find the data you're asking for.
Type - Types are the different categories of data, like users or products, and what details you can get about them.
Federation - This is a method to break a big GraphQL API into smaller, easier-to-manage pieces. Each piece handles a part of the API's job.
Subgraph - In a setup where an API is split into smaller pieces, each piece is called a subgraph. They each cover a part of the overall tasks the API can do.
Gateway - This is the main entrance for API requests in a setup with multiple subgraphs. It figures out which subgraph should handle a request and puts together the final result.
Pagination - This is a way to control how much data you get back from a query. It helps avoid getting too much information at once, which can be overwhelming.
Caching - Saving the results of queries so if the same request is made again, it can be answered quickly without having to ask the database again. This speeds things up a lot.
Data Loader - A tool that helps manage data requests more efficiently. It combines many requests into a single one and remembers previous requests to speed things up.
Appendix C - Frequently Asked Questions
Here are straightforward answers to some common questions about how GraphQL works and how to use it effectively:
What are some best practices for designing a GraphQL schema?
Here's what you should do:
- Build your schema to match what your app needs, not based on the backend systems
- Start simple and add more details as you go
- For linking data, use patterns like connections and edges
- Instead of removing old fields suddenly, plan to phase them out gradually
How can I implement authorization and permissions with GraphQL?
Here are some common ways:
- In resolver functions, add checks to make sure a user can access certain data
- Use an authentication system to manage who can access what
- Make sure queries don't expose sensitive information
- Use a gateway for managing access and directing requests to the right places
What are some ways to monitor and debug GraphQL APIs?
You can try:
- Apollo Studio for checking performance and finding issues
- GraphQL Playground for testing your queries by hand
- Use error handling tools to make errors consistent
- Logging tools can help track what's happening
How can I scale a GraphQL API across microservices?
You can:
- Split your schema into smaller pieces called subgraphs with Apollo Federation
- Use a gateway to combine these pieces into one big API
- Scale each piece according to its needs
- Improve performance with a CDN for caching
What are some common performance optimizations for GraphQL?
Try these:
- Turn on caching for your queries
- Use data loaders to group database requests
- Set limits on how complex queries can be
- Save often-used queries to speed things up
- Make sure your database is fast by adding indexes where needed
What are some ways to migrate an existing API to GraphQL?
Here's how:
- Begin by putting a GraphQL layer on top of your REST API
- Slowly move functions from REST to GraphQL
- Keep both APIs running at the same time for a while
- Combine APIs using schema stitching
- Gradually move users from REST to GraphQL
These answers should help you understand some key points about working with GraphQL. If you have more questions, just ask!
Related Questions
What is the architecture of GraphQL?
GraphQL works like a conversation between a customer (the client) and a shopkeeper (the server). The customer says exactly what they want, and the shopkeeper goes to get it, using a list (the schema) to find everything. There are helpers (resolvers) that pick out the items and a set way of writing the list (query language) so the shopkeeper understands.
What is GraphQL introduction?
Imagine GraphQL as a super-efficient way to get exactly what you need from the internet without any extra fuss. It's like ordering food with an app where you can customize your order down to the last detail.
What is the difference between GraphQL and rest architecture?
Think of GraphQL and REST like two different ways of ordering food. With GraphQL, you use one app to order anything you want, exactly how you want it. With REST, you might have to use different apps depending on what you're ordering, and you can't always customize your order as much.
What is the structure of GraphQL?
GraphQL has a blueprint (schema) that shows everything available for order. There are workers (resolvers) who find what you asked for, a special way to place your order (query language), and tools to make sure everything runs smoothly, like checking your order is right (validation) and helping if there are problems (error handling).


