

Practical hiring playbook for data engineers and analytics talent: clear roles, fast assessments, modern stacks, and transparency.
Hiring data engineers and analytics talent in 2026 is competitive and fast-moving. With demand for data engineers growing 23% annually and 2.9 million global data-related job openings projected this year, companies must act quickly and strategically to secure top candidates. Here’s what you need to know:
- Define roles clearly: Avoid vague job descriptions. Specify responsibilities, tech stacks (e.g., Snowflake, dbt, Airflow), and the challenges candidates will solve.
- Hire in the right order: Start with a Senior Data Engineer to establish pipelines, followed by an Analytics Engineer for data modeling, and then a Data Scientist or ML Engineer. (Review technical interview questions for data scientists to prepare for these roles.)
- Skills to prioritize: SQL, Python, cloud platforms (AWS, GCP, Azure), and tools like Spark, dbt, and Airflow. AI-related expertise, such as vector databases or LLM engineering, is increasingly valuable.
- Streamline hiring: Top candidates are off the market within three weeks. Use practical assessments like SQL challenges or pipeline design exercises, and offer compensation for take-home projects.
- Attract talent with transparency: Be upfront about your team’s size, data maturity, and tech challenges. Highlight opportunities for ownership and modernizing systems.
Key takeaway: Speed, clarity, and a focus on problem-solving skills are essential for hiring success in today’s competitive data landscape.
Data Team Roles: Data Engineers vs Analytics Talent
::: @figure 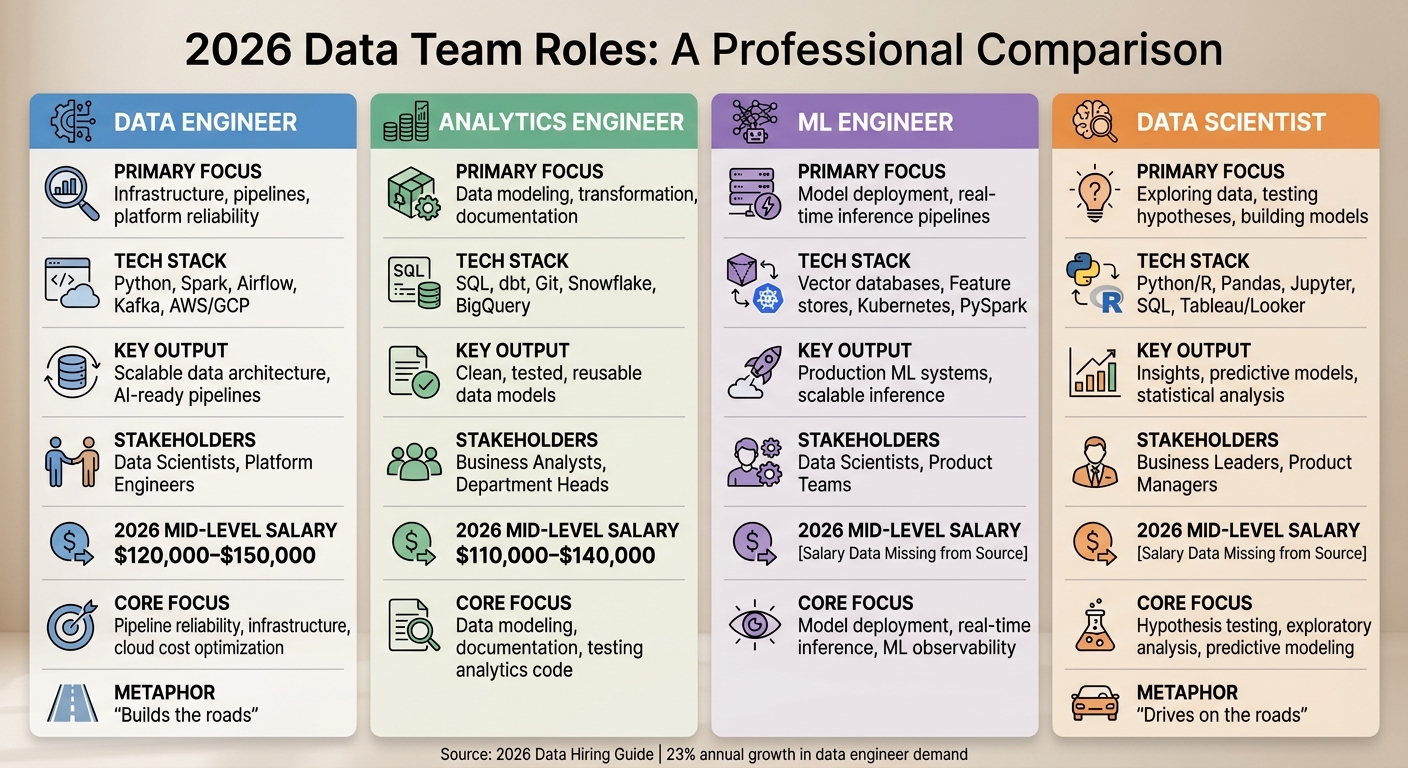 {Data Team Roles Comparison: Engineers vs Analytics vs ML vs Scientists 2026}
{Data Team Roles Comparison: Engineers vs Analytics vs ML vs Scientists 2026}
Recruiting for data roles in 2026 requires clear role definitions. Misunderstanding the distinctions between positions like data engineers and analytics engineers can lead to hiring mismatches. A data engineer isn’t just a data scientist with a different title, and an analytics engineer isn’t a junior version of a data engineer. Each role has its own responsibilities and requires technical and soft skill evaluation criteria.
Data Engineer vs Analytics Engineer
Data engineers focus on building and maintaining scalable data pipelines, managing cloud platforms (such as AWS, GCP, and Azure), and ensuring infrastructure reliability. Their toolkit often includes Python, Spark, Airflow, Kafka, and Kubernetes. With the rise of Retrieval-Augmented Generation (RAG) systems, they are increasingly tasked with managing vector databases and embedding pipelines . As Tom Kenaley from KORE1 describes it:
Data engineers build the roads. Data scientists drive on them .
On the other hand, analytics engineers handle the business logic layer. They transform raw data into clean, tested, and well-documented datasets. Their work revolves around SQL and dbt, where they apply software engineering best practices like version control and testing to data transformations. Unlike data engineers, who focus on the "Extract" and "Load" phases of the pipeline, analytics engineers concentrate on the "Transform" step within modern data warehouses like Snowflake and BigQuery .
In 2026, 41% of organizations report challenges due to unclear data ownership . To address this, data engineers typically take responsibility for data contracts and observability, while analytics engineers oversee the business logic layer .
| Feature | Data Engineer | Analytics Engineer |
|---|---|---|
| Primary Focus | Infrastructure, pipelines, platform reliability | Data modeling, transformation, documentation |
| Tech Stack | Python, Spark, Airflow, Kafka, AWS/GCP | SQL, dbt, Git, Snowflake, BigQuery |
| Key Output | Scalable data architecture, AI-ready pipelines | Clean, tested, reusable data models |
| Stakeholders | Data Scientists, Platform Engineers | Business Analysts, Department Heads |
| 2026 Mid-Level Salary | $120,000–$150,000 | $110,000–$140,000 |
ML Engineer vs Data Scientist
Data scientists are responsible for exploring data, testing hypotheses, and building models. They rely on tools like Python, R, Pandas, and Jupyter to conduct exploratory data analysis, statistical modeling, and pattern recognition. They operate as the "drivers" who depend on the infrastructure created by data engineers .
ML engineers, meanwhile, focus on taking these models into production. Their expertise lies in building infrastructure for model training, deployment, and real-time inference pipelines. They use tools such as vector databases, PyTorch, feature stores, and Kubernetes to ensure models perform at scale in production environments .
As DQLabs notes:
The failure point is almost never the model. It is the data infrastructure feeding it .
This insight underscores the importance of a proper hiring sequence. Start with a Senior Data Engineer to establish a solid foundation, followed by an Analytics Engineer to create usable data models, and only then bring in a Data Scientist or ML Engineer. Skipping these steps often leads to frustration, as data scientists end up spending their time cleaning unreliable data rather than building models .
Matching Roles to Tech Stacks
In 2026, candidates often value the tech stack as much as the salary. Being transparent about your tools and modernization plans can give you an edge in recruitment . Here’s how specific roles align with their respective technologies:
| Role | Tech Stack | Core Focus |
|---|---|---|
| Data Engineer | Spark, Airflow, Kafka, AWS Glue, Snowflake, Python | Pipeline reliability, infrastructure, cloud cost optimization |
| Analytics Engineer | dbt, SQL, Snowflake, BigQuery, Git | Data modeling, documentation, testing analytics code |
| ML Engineer | Vector databases, Feature stores, Kubernetes, PySpark | Model deployment, real-time inference, ML observability |
| Data Scientist | Python/R, Pandas, Jupyter, SQL, Tableau/Looker | Hypothesis testing, exploratory analysis, predictive modeling |
Combining tools like Spark, dbt, Kafka, and PyTorch in a single job description only confuses candidates. Instead, frame roles around the problems they’ll solve: for example, “Design pipelines with clear failure handling” (data engineer) or “Build reusable data models for revenue reporting” (analytics engineer).
With 72% of analytics professionals now using AI-assisted coding , the real bottleneck has shifted to areas like standards enforcement, documentation, and infrastructure reliability. Bruno Lima, Lead Data Engineer at phData, puts it this way:
AI is already great at writing code. The harder part, and where the real value is now, is everything around the code: tests, docs, observability, standards .
Ultimately, the best candidates aren’t those who know every tool by name, but those who understand when a simple solution is better than a complex one. Clearly defining roles and tech stacks not only improves recruitment but also ensures your team is equipped to tackle the challenges of modern data infrastructure.
sbb-itb-d1e6221
Skills to Assess When Hiring Data Engineers and Analytics Talent
Core Technical Skills: SQL, Python, Spark, dbt, Airflow
SQL and Python continue to dominate the data engineering landscape, appearing in over two-thirds of job postings as of 2026 . But it’s not just about basic proficiency - candidates need to demonstrate advanced SQL capabilities, like mastering window functions, optimizing joins, and diagnosing performance bottlenecks .
Python skills have also evolved. Beyond scripting, candidates should know how to build APIs, use tools like pytest for testing, and handle file processing in production environments . On top of that, expertise in emerging tech and AI-related areas is increasingly valuable. Skills like LLM engineering are now mentioned in 12% of data engineer job postings . Senior candidates should be prepared to discuss techniques such as chunking strategies, selecting embedding models, and managing vector databases effectively .
For orchestration tools like Airflow, Dagster, or Prefect, practical experience is key. Candidates should know how to define and manage DAGs, handle backfills, and troubleshoot failures . Analytics engineers, meanwhile, need to show strong command of dbt for tasks like data modeling, version control, and testing . While Spark is still relevant for handling large-scale data, it’s increasingly seen as a mid-level skill rather than an entry-level requirement .
Another critical area is data modeling. About one-third of interviews now focus on concepts like Kimball dimensional modeling, star schema design, and Slowly Changing Dimensions (SCDs) . Strong candidates can also demonstrate sound judgment, such as opting for a simple batch process instead of more complex distributed computing when it makes sense .
Finally, cloud expertise is a must, considering over 94% of enterprises now operate in the cloud .
Cloud Data Platforms and Certifications
Proficiency in at least one major cloud platform - AWS, Azure, or GCP - is a baseline requirement. Candidates should also be familiar with managed data warehouses like Snowflake, BigQuery, or Databricks .
Certifications, such as the Google Professional Data Engineer (valid for two years and costing $200 per exam), can serve as a useful benchmark for foundational knowledge . However, certifications alone don’t guarantee a candidate is ready for production environments. It’s more important that they understand cloud-native design principles, like choosing between serverless compute and managed services to balance scalability and cost .
In 2026, understanding FinOps is increasingly important. Data engineers are expected to optimize both performance and cost in cloud environments . Job postings requiring AI-related skills often offer a 43% higher salary, reflecting the demand for engineers who can build pipelines for machine learning workflows and manage vector databases for generative AI applications .
It’s also important not to overemphasize specific tools. For instance, someone with strong fundamentals in data warehousing (like experience with Redshift) can often pick up platforms like Snowflake or BigQuery in a matter of weeks . The focus should be on architectural thinking rather than tool-specific knowledge.
These skills are essential for building scalable, efficient systems in modern data engineering.
Hands-On Skill Evaluation Methods
While technical knowledge is critical, practical assessments are the best way to gauge a candidate’s real-world abilities. Research shows that abstract algorithm puzzles have a weak correlation (0.15) with job performance, while SQL challenges have a much stronger correlation (0.72) . This shift has led many companies to move away from LeetCode-style tests in favor of more relevant, job-specific evaluations.
For junior candidates, a 60-minute live SQL challenge can effectively test foundational skills. For senior roles, a 90-minute pipeline design exercise is recommended. This should assess architectural decisions (40%), the ability to handle failures (30%), scalability (20%), and communication skills (10%) .
Debugging simulations are another excellent tool for evaluating readiness for production environments. For example, you might present a broken pipeline scenario with logs and metrics, then evaluate the candidate’s troubleshooting process. Strong candidates will systematically identify issues like timezone discrepancies or schema changes . For senior roles, live working sessions lasting about 90 minutes can replace take-home projects and provide a better view of real-time problem-solving and collaboration skills .
If you use take-home projects, keep them under four hours and compensate candidates between $200 and $500 for their time . A typical project might involve building a pipeline that reads and transforms data while incorporating quality checks . Evaluation should include checks for idempotency (ensuring the pipeline produces consistent results regardless of how many times it runs) and robust error handling .
Finally, a consistent scoring rubric is essential to minimize bias. Separate technical performance from other factors like communication style and soft skills. Ask candidates how they would handle real-world scenarios, such as dealing with an API outage or resolving duplicate records. A focus on reliability and problem-solving is a strong predictor of success in this field .
Where to Find Data Engineers and Analytics Talent in 2026
Communities and Platforms for Data Professionals
The best data engineers often gather in technical communities to share knowledge and solve complex problems. One standout hub is the dbt Community, which boasts over 100,000 active members and organizes more than 50 global meetups each year. With over 80,000 teams using dbt weekly, this community offers a dense talent pool of modern data stack experts. When reaching out to potential candidates, highlight your tech stack - mentioning tools like dbt, Snowflake, or Airflow can significantly boost your chances of engaging experienced engineers.
GitHub remains a goldmine for finding top talent. By reviewing commit histories, issue discussions, and documentation, you can assess how candidates tackle systems-level challenges or use a tech candidate fit analyzer to score their skills. Slack groups and niche forums also offer a glimpse into engineers' problem-solving skills. For data scientists and machine learning engineers, platforms like Kaggle provide objective metrics such as competition rankings and notebook quality. Meanwhile, HackerRank introduced a RAG (Retrieval-Augmented Generation) assessment suite in April 2025, tailored to identify AI-focused data engineers.
"The best sourcing message is short and specific. Mention the actual problem, the level of ownership, and the kind of decisions the person would make." - MyCulture.ai
When sourcing, be transparent about your team size, the maturity of your data processes, and the challenges the candidate will face. This clarity, combined with a focus on your tech stack, helps attract candidates who are a strong fit for your needs.
To complement these community-driven strategies, specialized tools can help uncover passive talent.
Using daily.dev Recruiter for Data Talent Sourcing
Many top data engineers aren’t actively job hunting. daily.dev Recruiter bridges this gap by analyzing developers' professional reading habits and tech stack preferences. It connects you with candidates where they naturally spend time - engaging with technical content and exploring emerging tools like vector databases or trending topics in data engineering.
This platform uses warm, double opt-in introductions, ensuring that you only engage with candidates who are genuinely interested. It pre-qualifies developers based on their interests in technologies like Python, Spark, or dbt. For data roles, this method works exceptionally well - engineers reading about Airflow orchestration or Snowflake optimization are signaling their expertise and commitment to staying current.
"The best people rarely need to apply for anything... they're being recruited directly." - Tom Kenaley, President, KORE1
Integrating seamlessly with ATS and other sourcing tools, daily.dev Recruiter simplifies candidate management and aligns with your hiring workflow. With global data-related job openings projected to hit 2.9 million in 2026 and demand for data engineers growing 23% annually, passive sourcing through professional networks is becoming the go-to strategy for finding high-quality talent.
Local Meetups and Remote Talent Pools
In addition to online platforms, in-person events and remote hiring can expand your talent search. Attending local meetups allows you to observe candidates in action and build relationships over time. This keeps your company visible to passive candidates who might not be actively job hunting. For example, the dbt Community hosts over 50 global meetups annually, and events like the dbt Summit (scheduled for Las Vegas in September 2026) attract thousands of active practitioners.
When asking for referrals, be specific. Instead of requesting "good data engineers", ask for "people who simplify systems well".
For remote hiring, time zone compatibility often outweighs cost considerations. Hiring candidates within a 3–4 hour time zone overlap helps avoid delays in collaboration. Remote work has also narrowed salary differences, increasing competition for top talent. Managing remote teams effectively requires clear documentation, well-defined processes, and at least one senior on-site leader to oversee distributed professionals.
Speed is critical when hiring remotely - top candidates often accept offers quickly. Aim to complete your hiring process within three weeks to stay competitive.
Technical Assessments and Interview Strategies for Data Roles
Take-Home Projects vs Whiteboard Challenges
Whiteboard interviews often fall short when it comes to evaluating technical skills without coding tests when building reliable data pipelines. For instance, performance on SQL challenges shows a strong correlation (0.72) with actual job success, whereas algorithm puzzles barely register at 0.15 . This highlights how algorithm-based tests often fail to reflect the real-world demands of data roles.
When using take-home projects, keep them concise - around 3–4 hours - and follow up with a review session to discuss the candidate's design decisions. For example, you might ask candidates to create a pipeline that calculates Customer Lifetime Value from CSV files. Include tasks like data quality checks and documentation to gauge how they handle trade-offs between cost, latency, and complexity .
For senior-level roles, consider 90-minute live working sessions to evaluate problem-solving and collaboration in real time . To make the process more appealing and equitable, offer compensation for take-home projects - anywhere between $200 and $500 . Additionally, aim to keep the entire interview process under five hours and extend offers within three weeks to maintain momentum and attract top talent .
With these steps in place, the next focus should be on assessing candidates' expertise with specific tools and frameworks.
Testing Specific Tools and Frameworks
After evaluating general problem-solving skills, shift attention to tool-specific assessments that simulate everyday tasks. As noted earlier, aligning challenges with your tech stack (e.g., SQL, Airflow, dbt) ensures candidates are prepared for the actual work they'll face.
Design tasks that reflect end-to-end pipeline architecture for real business use cases. For SQL challenges, tailor the complexity to the role:
- Junior roles: Basic joins and aggregations
- Mid-level roles: Window functions and date handling
- Senior roles: Complex logic composition and query optimization
These tests should emphasize judgment over memorization . For example, present a scenario where candidates must ingest API data for fintech loan processing. Then ask probing questions like, "What happens when the API is down?" or "How would you handle PII?" Such questions reveal how candidates think through real-world issues . Similarly, system design communication skills, which correlate strongly (0.68) with workplace success, can be evaluated through these exercises .
Debugging simulations are another effective way to test readiness for production environments. Present a broken pipeline scenario - such as a 30% revenue drop - along with logs, queries, and metrics. Observe how candidates systematically troubleshoot issues like timezone errors, schema changes, or duplicate records. Debugging skills show a 0.65 correlation with performance in live environments .
"Fluency in tools can be superficial; true capability is shown by strong judgment." – MyCulture.ai
Tailor assessments to the role’s requirements. For Analytics Engineers, focus on SQL complexity and dbt-specific modeling. For Platform Engineers, emphasize Python skills, infrastructure-as-code tools like Terraform, and orchestration platforms such as Airflow or Dagster . Each test should mirror the tools and challenges the candidate will face daily.
Assessment Type Comparison Table
| Assessment Method | Best For | Pros | Cons |
|---|---|---|---|
| Live SQL Challenge | All levels | Strong correlation with job performance (0.72) | Can be stressful for some candidates |
| Pipeline Design | Senior/Staff | Tests architectural judgment and trade-offs | Demands highly skilled interviewers |
| Debugging Simulation | Mid/Senior | Evaluates production troubleshooting skills | Challenging to create realistic scenarios |
| Take-Home Project | Junior/Mid | Highlights code quality and documentation | Time-intensive; risk of dishonesty |
| Live Working Session | Senior+ | Shows real-time collaboration style | Requires significant interviewer time |
To ensure fairness and reduce bias, use structured rubrics to score candidates on dimensions like "Reliability Mindset" and "Pragmatism" . Look for green flags such as clarifying constraints before proposing solutions or discussing monitoring strategies proactively. Red flags include jumping to overly complex solutions without addressing factors like SLA, cost, or data volume .
Competing with Big Tech for Data Talent
Equity and Ownership Opportunities
Big Tech companies often lure senior data engineers with total compensation packages that can exceed $300,000 . Startups, while unable to match those figures outright, bring something different to the table: the chance to make a bigger impact and gain more ownership. In a smaller team, an AI-native data engineer can have a 30–50× impact on the business . Compare that to a FAANG role, where an engineer might only manage a single microservice within a vast system.
Startups stand out by offering full ownership of projects. Smaller teams often combine data and analytics functions, giving engineers the chance to oversee the entire lifecycle of their work instead of being confined to a narrow set of tasks . Guillaume Belisle from VertAI captures the frustration of being underutilized in larger enterprises:
"The most expensive janitor in the world is a senior data scientist... We bought a Formula 1 driver... and we asked them to pave the track."
At startups, data professionals get to build foundational infrastructure instead of just maintaining legacy systems.
"Data professionals leave when they feel like report factories rather than strategic partners." – Ben, Head of Data Strategy
Offering hybrid roles, like AI Data Engineer positions that combine traditional data engineering with exposure to tools like RAG and LLM orchestration, can also be a game-changer. Roles requiring multiple AI-related skills offer a 43% salary premium, and around 45% of data and analytics positions now reference AI-specific expertise . This approach not only boosts the role's impact but also aligns with the growing demand for strategic, career-enhancing opportunities.
Modern Tech Stacks and Flexible Work Policies
Startups also attract top talent by embracing modern tech stacks and flexible work policies. Tom Kenaley, Senior Partner and President at KORE1, notes that smaller companies can move quickly, avoiding the red tape that often slows down larger organizations .
To stay competitive, keep your hiring process efficient - aim to close from the first screen to an offer within three weeks. By 2026, top-tier candidates rarely stay on the market longer than that . Highlighting the use of cutting-edge tools like dbt, Snowflake, and Airflow in your job postings can double your offer acceptance rates . If your company is still working with legacy systems, be upfront about it. Many engineers are drawn to the challenge of modernizing outdated systems rather than simply maintaining them .
Startups also have the advantage of agility. While larger, regulated companies may struggle to adopt practices like agentic data engineering or Bring-Your-Own-Agent (BYOA) patterns, smaller teams can pivot quickly . This appeals to candidates who want to work with the latest technology and avoid the slow-moving processes of corporate giants.
Transparency About Team Size and Data Maturity
By 2026, data engineers are weary of vague "data" roles. Being transparent about your team's size, technical debt, and the maturity of your infrastructure can attract candidates who want to build robust systems .
"The best candidates often avoid jobs that promise greenfield elegance when the work primarily involves cleanup, standardization, and stakeholder negotiation."
In your job descriptions, frame responsibilities as challenges to tackle. For instance, instead of generic statements, say something like, "Build pipelines with clear failure handling so downstream teams can trust outputs" . Clearly outline the scope of the role, the team structure, and the authority the candidate will have to improve existing systems.
A streamlined hiring process also matters. Elite engineers see a chaotic recruitment loop as a red flag for an equally disorganized production environment. Fast scheduling and clear feedback during interviews signal that your company values efficiency and quality . Additionally, with 22% of data engineers citing a lack of leadership direction as a major pain point, providing a clear vision and maintaining flatter hierarchies can set your organization apart . This level of transparency and organization reassures candidates that they'll be empowered to make an impact from day one.
Conclusion
Hiring data engineers and analytics professionals in 2026 demands a sharp focus on clarity, efficiency, and openness. With demand surging by around 23% annually and an estimated 2.9 million data-related job openings worldwide, vague job descriptions and sluggish hiring processes can lead to missed opportunities for securing top candidates. Start by clearly defining roles: data engineers focus on creating solid infrastructure, analytics engineers turn data into actionable insights, and ML engineers specialize in deploying AI systems. Expecting one person to master all these areas is unrealistic and counterproductive.
Look beyond technical skills and assess decision-making abilities. While proficiency in tools like SQL and Python is important, standout candidates excel at balancing trade-offs, such as cost versus performance or batch versus streaming solutions. Use take-home assignments that take no more than four hours to evaluate practical skills like handling errors and managing schema drift. Offering compensation between $200 and $500 for these projects not only tests their expertise but also demonstrates respect for their time and effort.
Speed matters. The best candidates, often juggling multiple offers, appreciate a hiring process that wraps up in less than three weeks. Clear communication about expectations, especially regarding modern versus outdated tools, can make your offer stand out in this competitive market.
FAQs
What’s the fastest hiring process that still works for data roles?
By 2026, the hiring process for data roles is all about practical, real-world assessments. Instead of dragging candidates through endless interview rounds, focus on targeted evaluations that test the skills that actually matter.
For instance, consider using take-home projects like building data pipelines or coding exercises to gauge expertise in SQL, Python, and cloud platforms. These hands-on tasks provide a clear picture of a candidate’s technical abilities.
But don’t stop there - behavioral interviews remain crucial. They help you understand how candidates communicate and collaborate, ensuring they’re a good fit for your team. This approach keeps the process efficient while maintaining high standards.
How do I choose between a Data Engineer and an Analytics Engineer first?
In 2026, choosing between a Data Engineer and an Analytics Engineer hinges on where your organization stands with its data infrastructure. If your data is fragmented across multiple systems and you lack a warehouse or dependable pipelines, bringing in a Data Engineer is the logical first step. They can create the scalable infrastructure you need. On the other hand, if you already have a centralized data warehouse in place but struggle to extract insights or streamline workflows, an Analytics Engineer is the better fit. Their expertise lies in improving data modeling and making your data easier to access and use.
What should a real-world data engineering interview test include?
When it comes to data engineering interviews, a practical test is essential to gauge a candidate's ability to design, build, and maintain robust, production-ready data systems. Here's what such a test typically involves:
- Designing data pipelines: Candidates might be tasked with creating pipelines for either real-time or batch data processing, demonstrating their understanding of both approaches.
- Selecting storage solutions: They need to choose between options like a lakehouse or a data warehouse, based on the project's requirements.
- Balancing trade-offs: This includes evaluating aspects like data modeling, governance, and cost to ensure the system is efficient and scalable.
These exercises are designed to reflect the challenges of managing large-scale, dependable data systems while leveraging modern tools and architecture strategies.


